Jam's story
영화 댓글 자연어 처리 본문
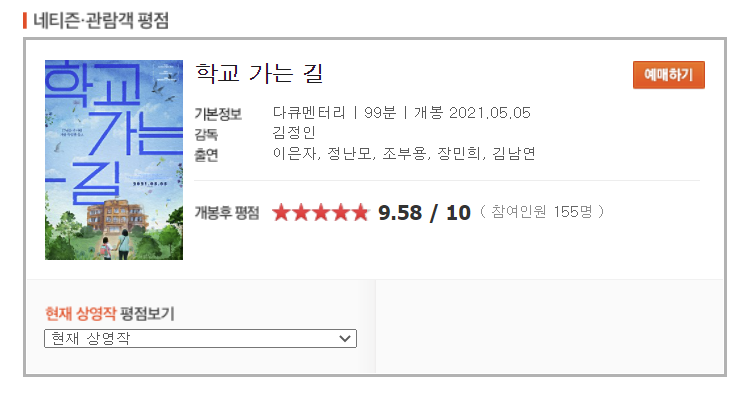
크롤링한 영화 -> 네이버 영화 (naver.com)
참고목록
네이버 영화 리뷰 크롤링 #1 : 네이버 블로그 (naver.com) 참고함
2.크롤링(2): 나도 할 수 있다. 크롤링!!!.. : 네이버블로그 (naver.com)
3.# Text Analysis(1) - 영화댓글.. : 네이버블로그 (naver.com)
라이브러리 로드

댓글 크롤링

soup=bs(response.text, 'html.parser') -> html태그를 없애준다
* .text를 꼭 붙여야함
웹페이지에서 F12를 누르고 (ctrl+shift+i )눌러도됨
찾고싶은 곳을 클릭하면 해당하는 블록에 대한 태그가 뜬다.


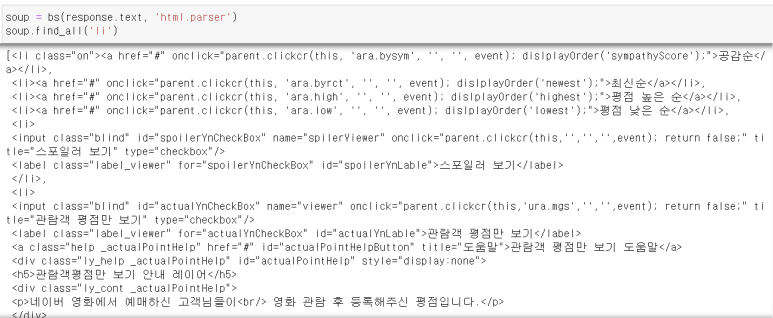
score_result div 박스 안에 li 안에 a , 이것이 댓글이고 em이 점수이다.
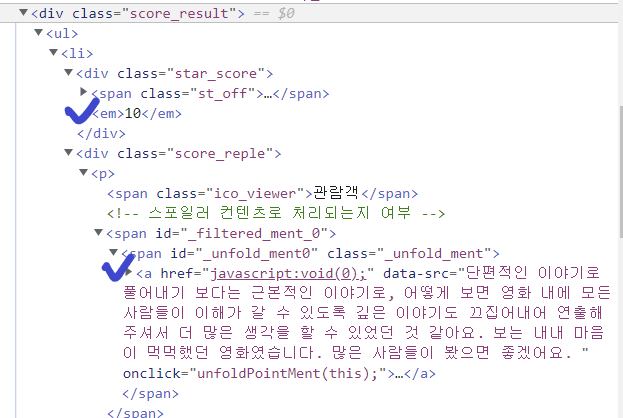
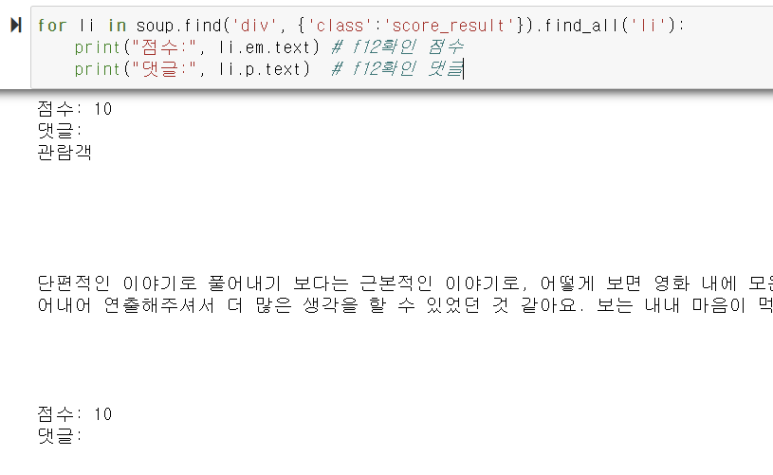
score_result에서 모든 li를 찾아 그 li의 em과 p를 출력
이것을 함수로 만들음
(page=1 )-> 1페이지만 한것
score 이랑 text에 담아줌
계속 한페이지만 불러오게 되었는데
response = requests.get('https://movie.naver.com/movie/bi/mi/pointWriteFormList.naver?code=197071&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false&page= %s'%page) 이렇게 바꿔야함



데이터를 불러온다

데이터 전처리
네트워크 오류 등으로 인한 중복값 지우기
"text"가 중복인것들을 가장최근것으로 남기겠다는 뜻
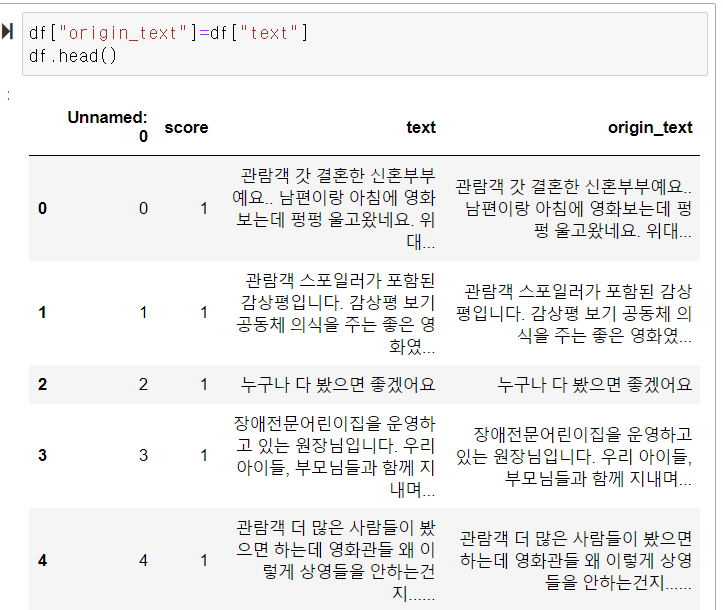
df=df.drop_duplicates(["text"], keep="last")
중복제거후 df.shape 해보니 댓글 수가 줄어듬

전처리 하기 전에원본 보존하기