
Jam's story
크롤링 본문
크롤링
크롤링할 페이지.robots.txt 해서
허용하는지 허용안하는지 목록이 나와있음

시작
# 라이브러리 로드
# requests는 작은 웹브라우저로 웹사이트 내용을 가져온다.
import requests
# BeautifulSoup 을 통해 읽어 온 웹페이지를 파싱한다.
from bs4 import BeautifulSoup as bs
# 크롤링 후 결과를 데이터프레임 형태로 보기 위해 불러온다.
import pandas as pd
#여러페이지를 읽어올때 진행상태를 확인하는 목적
from tqdm import trange
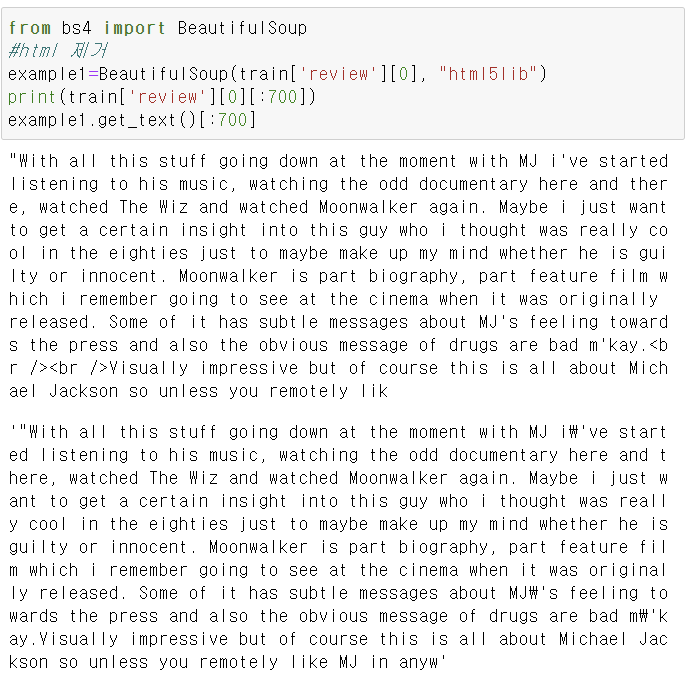
requests.get으로 웹페이지 내용을 가져온다.
.text를 붙이면 html 태그까지 붙어있는 데이터 그대로 보여준다.
<html> 태그없애기

이 태그로도 html 태그를 제거할 수 있다.
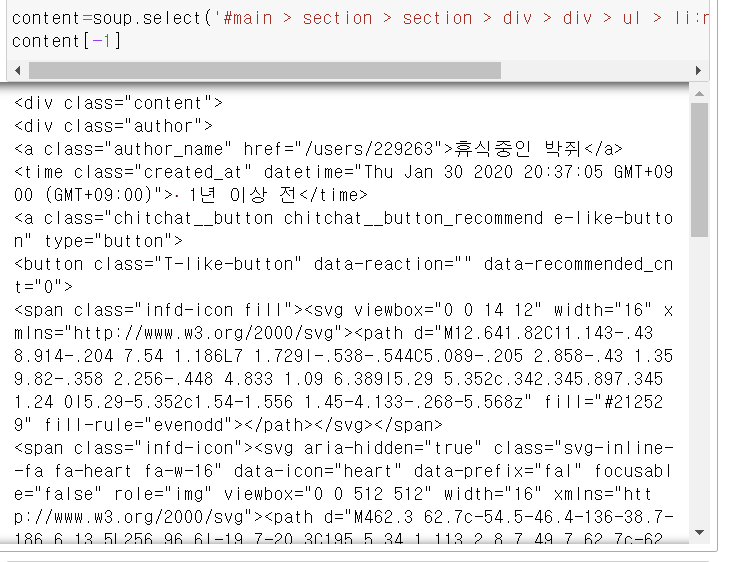
댓글을 가져오기
가져오고싶은댓글+오른쪽마우스- >검사 하면 창이 뜬다
아니면 ctrl +shift+i

댓글 전체를 가져오고 싶다면
content 부분을 오른쪽마우스 - copy- copy selecter


[0]을 안붙이면 이렇게 리스트 형태로 나타난다.

[0]을 붙이면 리스트가 분리가 된다,

.get_text(strip=True)
앞뒤 공백제거하고 원하는 텍스트만 가져온다


이걸로 성공함
'2021-2학기 > 데이터분석' 카테고리의 다른 글
| 영화 댓글 자연어 처리 (0) | 2022.03.23 |
|---|---|
| 데이터정제 (0) | 2022.03.23 |
| 영화리뷰 감정분석 (0) | 2022.03.23 |
| 서울종합병원분포 알아보기 (0) | 2022.03.23 |
| Pandas 3주차 (0) | 2022.03.23 |
'2021-2학기/데이터분석' Related Articles
more



