
Jam's story
자연어 처리 본문
데이터정제
BeautifulSoup(뷰티풀숩)을 통해 HTML 태그를 제거
정규표현식으로 알파벳 이외의 문자를 공백으로 치환
NLTK 데이터를 사용해 불용어(Stopword)를 제거
어간추출(스테밍 Stemming)과 음소표기법(Lemmatizing)의 개념을 이해하고 SnowballStemmer를 통해 어간을 추출
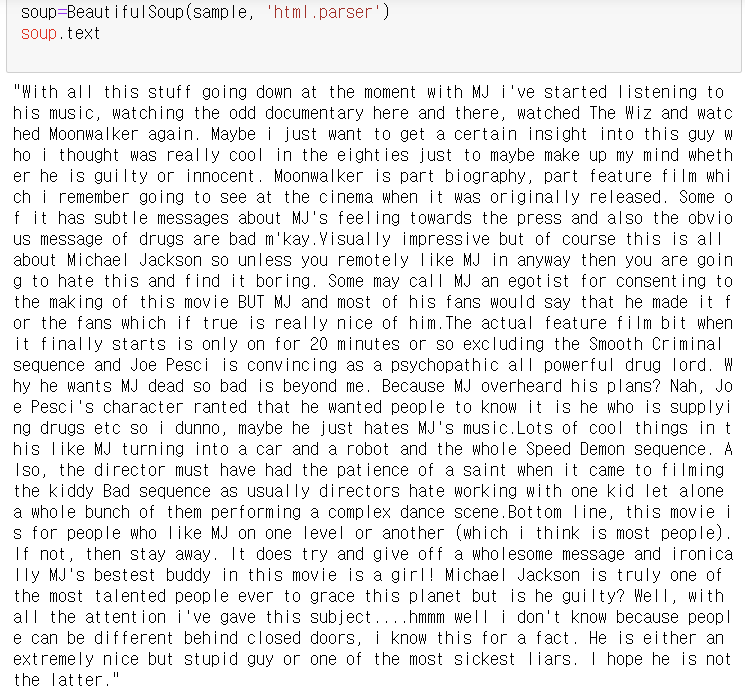
html태그제거
soup=BeautifulSoup(sample, 'html.parser')
soup.text
(.text 를 추가하는 것 까먹지 말기 )

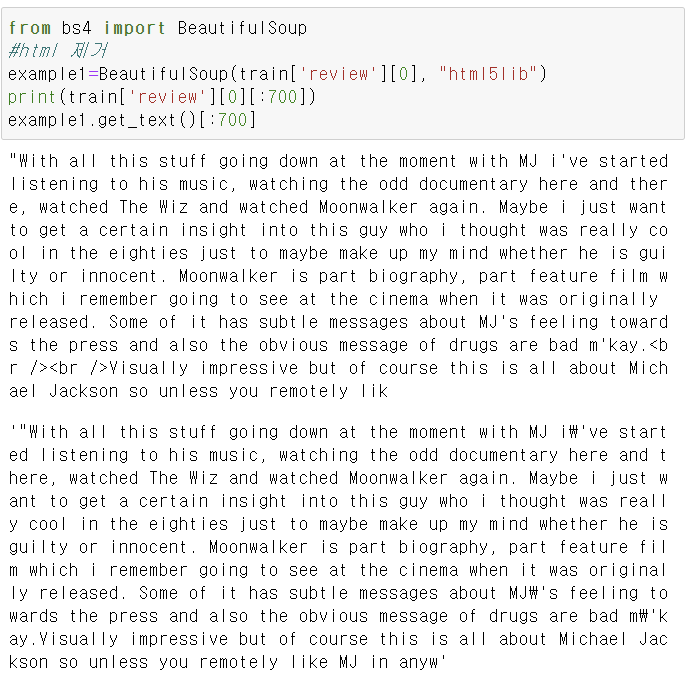
이 방법으로도 html 제거를 할 수 있다.
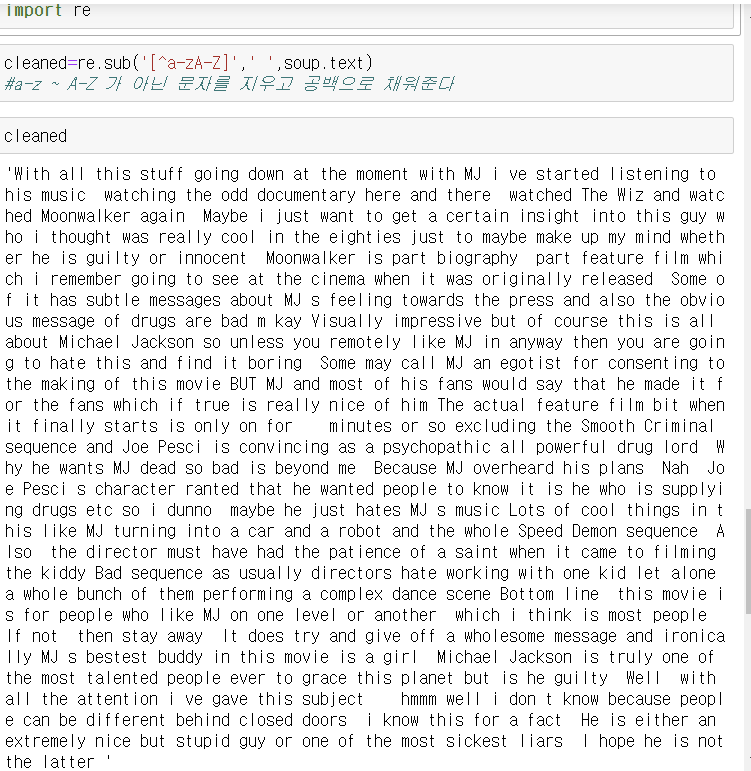
특수기호제거
import re -> 정규표현식을 이용해서 특수문자 제거
re.sub('[^a-zA-Z]' , ' ' , soup.text)
a-z ~ A-Z가 아닌 문자를 지우고 공백으로 채워준다
cleaned 변수에 넣고 출력
모두 소문자로 바꾼다- With 랑 with는 다르게 인식하기 때문에 순수하게 단어만 보기 위해서

stopwords
오류처리- [Resource stopwords not found]

eng_stopwords(불용어) 를 출력
불용어 (조사 - 은는이가, 자주쓰이지만 의미없는 단어

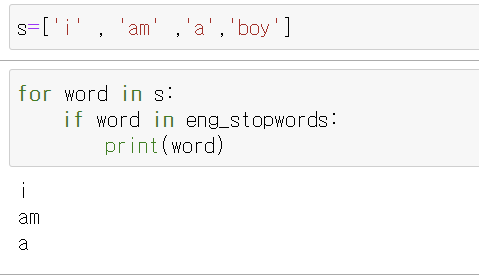
i , am, a, boy 가 불용어 사전에 있는지 확인 -> i , am, a만 존재 (얘네만 불용어 사전에 포함 )
이제 이것을 없앨것
sample 을 소문자로 바꾸고, 단어별로 나눔
이 단어들을 for문을 통하여 각각이 불용어사전에 포함되는지 검사
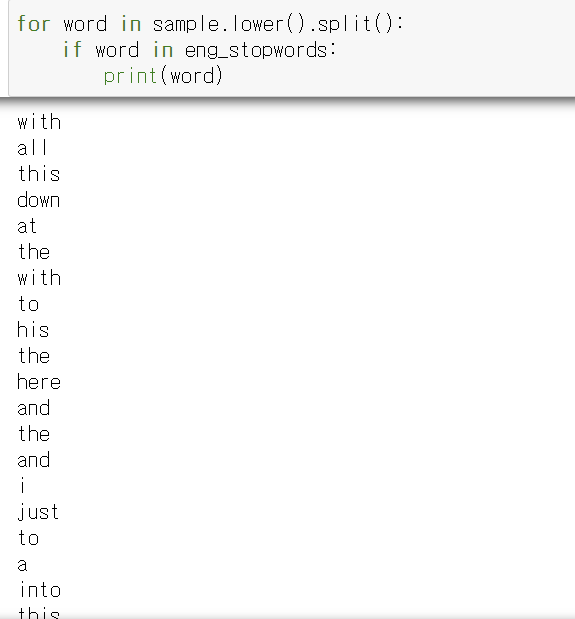
from nltk.corpus import stopword을 이용
이제 이 과정을 아까 그 함수에 넣어줌

이미 소문자 처리된 cleaned 변수를 split()로 단어별로 쪼개준다.
이 단어가 불용어 사전에 없다면 cleaned에 저장하기
return cleaned 를 하면 단어별로 쪼개서 나오고
문장처럼 출력하고 싶다면 return' '.join(cleaned)

train,unlabeld_train, test 데이터를 한번에 모아서 처리하기 위해 pd. concat 을 사용해서 모아준다
preprocessing 함수를 사용해서 의미없는 단어들을 없애준다


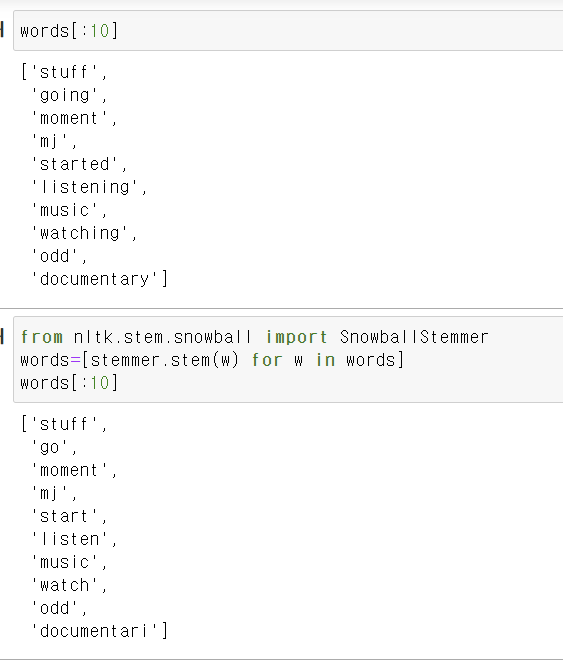
스태밍 -어간 추출
어간 추출은 어형이 변형된 단어로부터 접사 등을 제거하고 그 단어의 어간을 분리해 내는 것
"message", "messages", "messaging" 과 같이 복수형, 진행형 등의 문자를 같은 의미의 단어로 다룰 수 있도록 도와준다.
NLTK에서 제공하는 형태소 분석기를 사용
포터 스태머 사용방법 과 랭커스터스태머 사용 방법
어떤스태머이냐에 따라서 결과도 다르다 .예) maximum

어간 변경
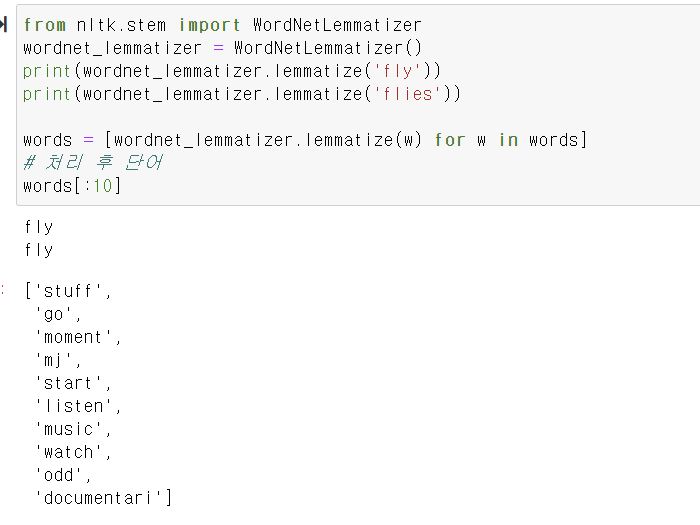
음소표기법 -Lemmatization
레마타이제이션은 이때 앞뒤 문맥을 보고 단어의 의미를 식별하는 것
배 - 먹는 배 , 타는 배, 몇 배 등 동음이의어가 문맥에 따라 다른 의미를 가진다.
meet- meeting은 회의, meet 만나다 명사로쓰였는지, 동사로 쓰였는지에 따라 적합한 의미를 갖도록 추출
지금 까지 한 것을 함수로 만들고 적용

'2021-2학기 > 데이터분석' 카테고리의 다른 글
| 2021 K-ICT 데이터크리에이터 최우수상 수상 (0) | 2022.03.25 |
|---|---|
| 자연어처리 영화댓글 (0) | 2022.03.23 |
| 자연어처리 형태소 분석 (0) | 2022.03.23 |
| 영화 댓글 자연어 처리 (0) | 2022.03.23 |
| 데이터정제 (0) | 2022.03.23 |


