
Jam's story
영화리뷰 감정분석 본문
(7) EP.02 [캐글뽀개기] 영화 리뷰 감정분석 - 데이터 불러오기 - YouTube 참고함
데이터 출처 : Bag of Words Meets Bags of Popcorn | Kaggle
캐글 대회인 "Bag of Words Meets Bags of Popcorn" 진행을 통해 머신러닝과 딥러닝을 활용한 다양한 접근으로 전처리부터 예측까지
데이터전처리
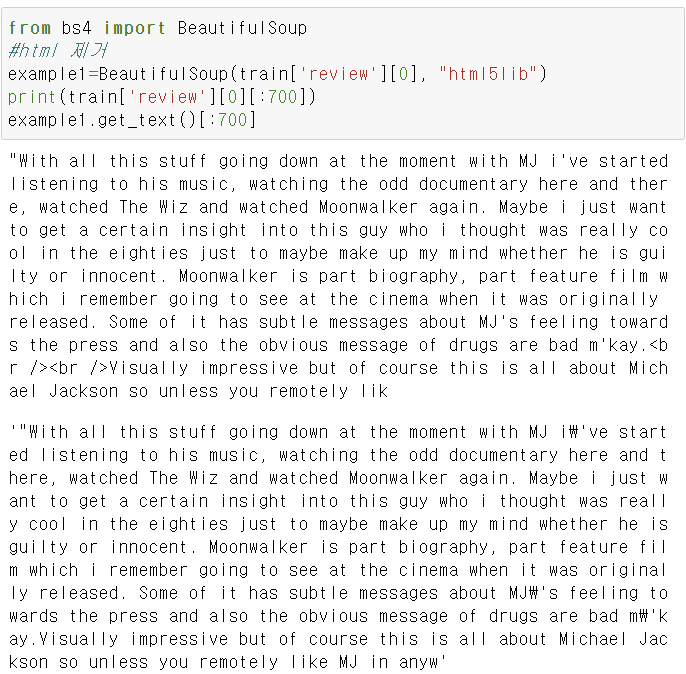
beutiful Soup을 이용하여 html 태그를 제거,
from nltk.corpus import stopword을 이용하여 불용어 (조사 - 은는이가, 자주쓰이지만 의미없는 단어

html태그제거
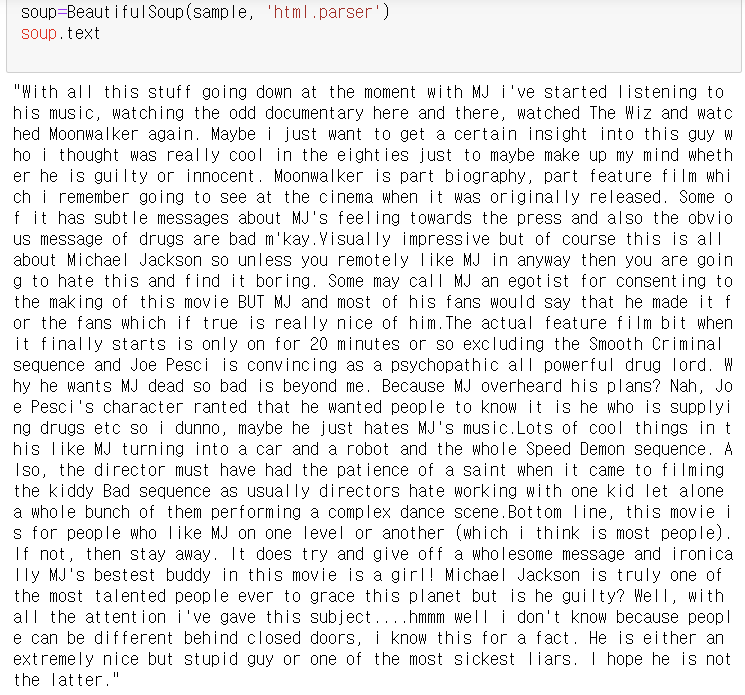
soup=BeautifulSoup(sample, 'html.parser')
soup.text
(.text 를 추가하는 것 까먹지 말기 )
이 방법으로도 html 제거를 할 수 있다.
특수기호제거
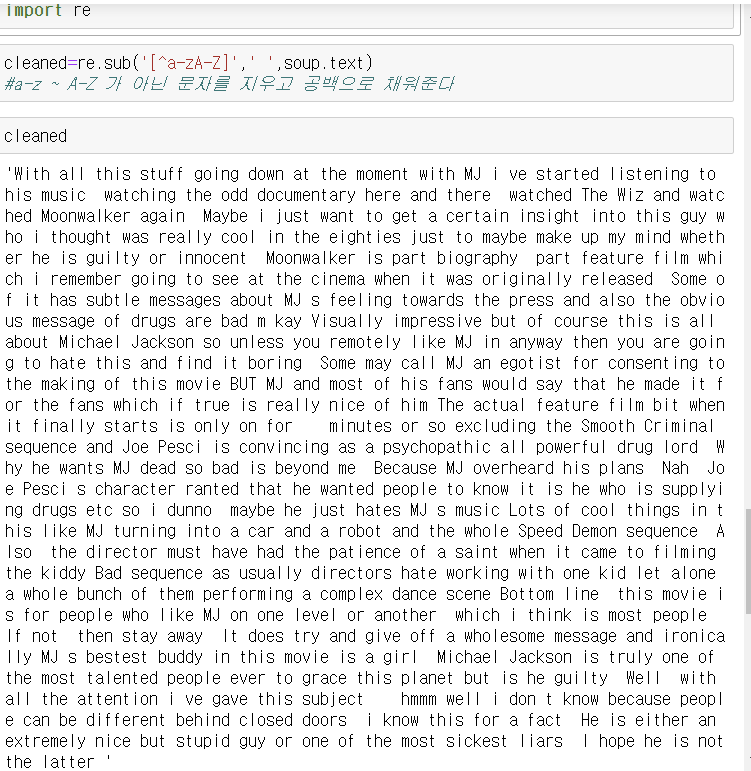
import re -> 정규표현식을 이용해서 특수문자 제거
re.sub('[^a-zA-Z]' , ' ' , soup.text)
a-z ~ A-Z가 아닌 문자를 지우고 공백으로 채워준다
cleaned 변수에 넣고 출력
모두 소문자로 바꾼다- With 랑 with는 다르게 인식하기 때문에 순수하게 단어만 보기 위해서

지금까지의 과정을 함수로 만들어준다

stopwords
오류처리- [Resource stopwords not found]
eng_stopwords(불용어) 를 출력

i , am, a, boy 가 불용어 사전에 있는지 확인 -> i , am, a만 존재 (얘네만 불용어 사전에 포함 )
이제 이것을 없앨것
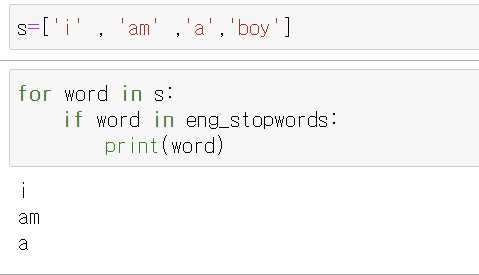
sample 을 소문자로 바꾸고, 단어별로 나눔
이 단어들을 for문을 통하여 각각이 불용어사전에 포함되는지 검사
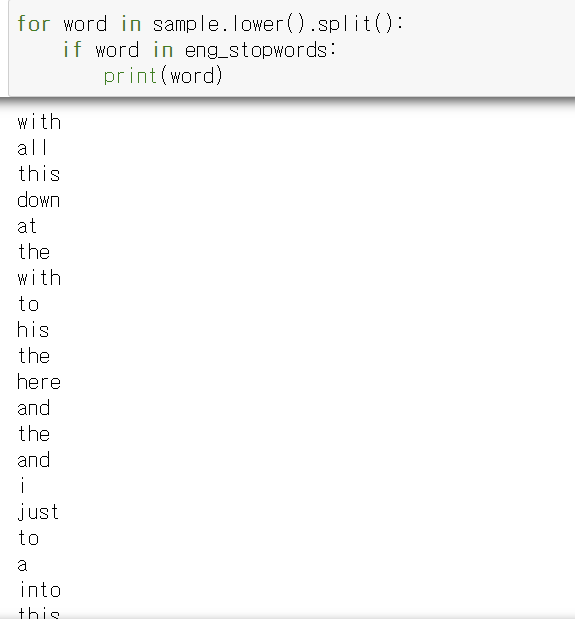
이제 이 과정을 아까 그 함수에 넣어줌

이미 소문자 처리된 cleaned 변수를 split()로 단어별로 쪼개준다.
이 단어가 불용어 사전에 없다면 cleaned에 저장하기
return cleaned 를 하면 단어별로 쪼개서 나오고
문장처럼 출력하고 싶다면 return' '.join(cleaned)
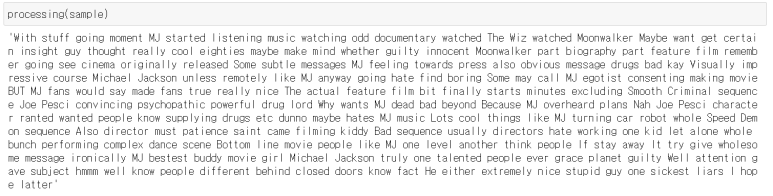
train,unlabeld_train, test 데이터를 한번에 모아서 처리하기 위해 pd. concat 을 사용해서 모아준다
preprocessing 함수를 사용해서 의미없는 단어들을 없애준다


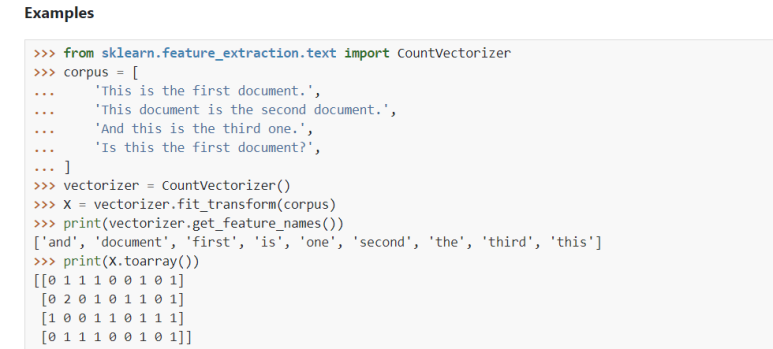
CountVectorizer
: 단어들의 카운트(출현 빈도(frequency))로 여러 문서들을 벡터화
카운트 행렬, 단어 문서 행렬 (Term-Document Matrix, TDM))
모두 소문자로 변환시키기 때문에 me 와 Me 는 모두 같은 특성이 된다.
analyzer은 word기준으로 설정, max_features -> 빈도수가 높은것 5000개 지정
-99998개 데이터에 , 5000개 칼럼
-to.array()[0] 를 해서 볼 수 있음
아까 모았던 데이터를 다시 쪼갠다.
test데이터는 끝에서 부터 쪼개기 때문에 - len(test):

y값을 만들어준다

모델을 만들어서 예측
max_depth ->
n_jobs -> 학습할때 모든 코어를 활용해라

'2021-2학기 > 데이터분석' 카테고리의 다른 글
| 데이터정제 (0) | 2022.03.23 |
|---|---|
| 크롤링 (0) | 2022.03.23 |
| 서울종합병원분포 알아보기 (0) | 2022.03.23 |
| Pandas 3주차 (0) | 2022.03.23 |
| 목차 칼럼명 뽑기 (0) | 2022.03.23 |



