
Jam's story
서울종합병원분포 알아보기 본문
서울종합병원분포 알아보기 - folium이용
open-data-analysis-output.ipynb - Colaboratory (google.com) 참조하였음

폰트를 선명하게 보이게 하기- > set _matplotlib_formats('retina')
그래프가 노트북 안에 보이게 하기 -> %matplotlib inline
데이터 로드하기
-read_csv 사용
-df 변수에 넣는다
-shape를 이용하여 데이터 갯수를 출력한다. 결과는 행 ,열 순으로
-head() , tail()로 미리보기
-sample()로 미리보기
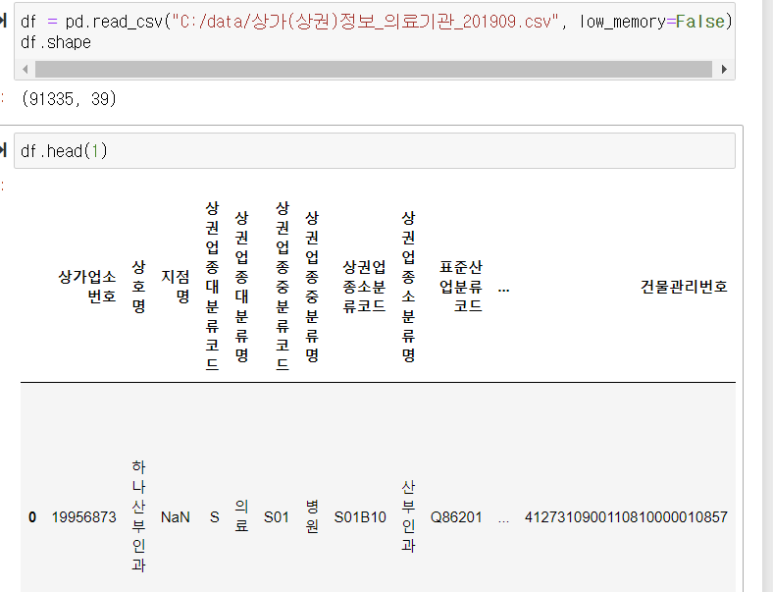
데이터 요약
data.info()

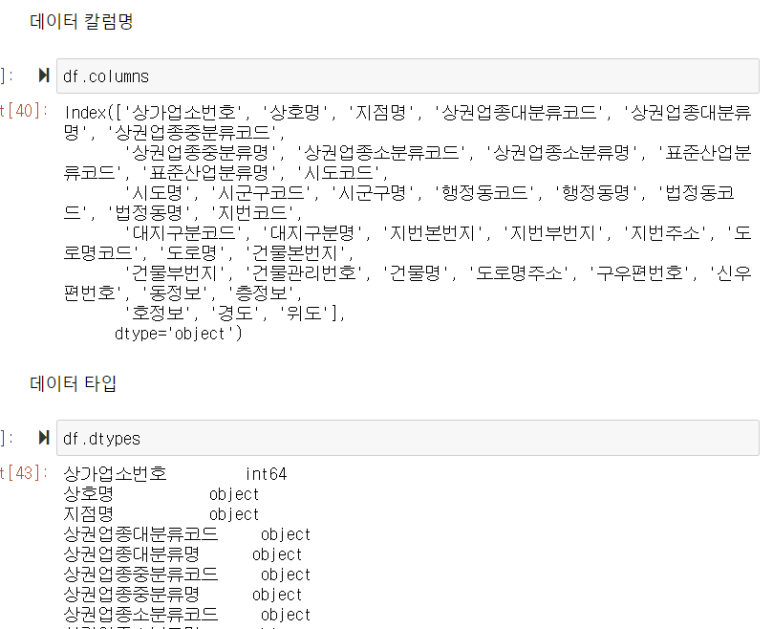
데이터 칼럼명 검색 ->df.columns
데이터 타입 검색 -> df.dtypes
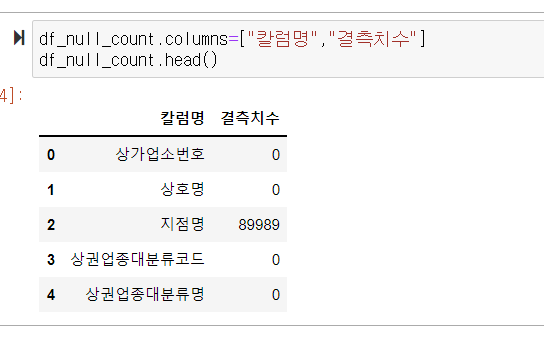
데이터 결측치 ->isnull()

이 결측치로 plot.bar를 통해 막대그래프로 표현
df.isnul().sum().plot.barh(figsize=(10,7))

.reset_index()
기능
1)판다스 데이터프레임의 인덱스를 리셋.
2)간혹 특정 데이터 프레임의 부분을 다른 데이터 프레임으로 만들거나,
3)데이터 프레임들간의 조합으로 새 데이터 프레임을 만들 경우 기존 인덱스가 남아있는 경우가 있는데,
이 때 인덱스를 리셋하여, 단순 순차적 인덱스를 생성함
이 계산한 결측치 수를 reset_index() 로 데이터 프레임으로 만들어줌
df_null_count 변수에 결과를 담아 열어보기

칼럼명 변경
.columns=["" ,"" ... ]
정렬
sort_values를 통해 정렬한다.

특정칼럼만 불러오기
[ ] 안에 써넣어 지점명 컬럼을 불러온다
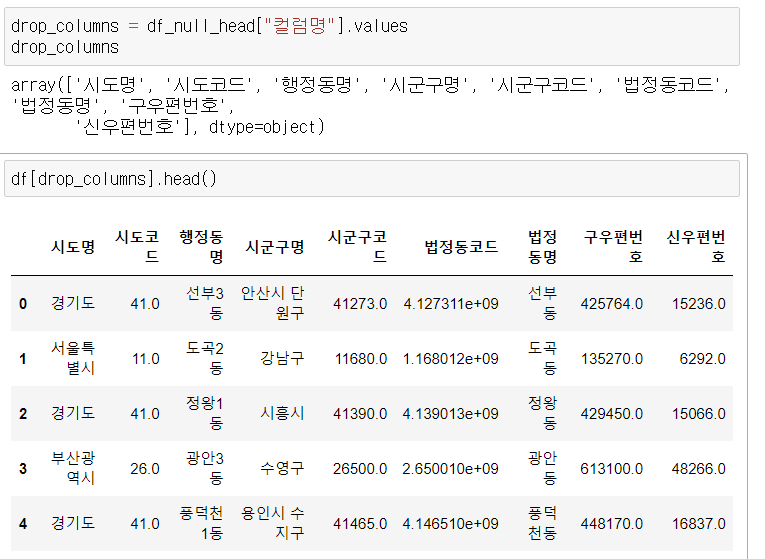
제거하기 -drop
axis=0 인덱스 기준 ( 기본값) axis= 1 칼럼 기준
.drop(columns=drop_columns) drop_columns 열을 삭제할경우

기초통계
평균값 - > .mean()
중앙값 -> .median()
최댓값 -> .max()
최솟값 -> .min()
갯수 -> .count()
기초통계값 요약하기
df[" " ].describe()
df[["" ,""]]. describe()
문자열 데이터타입의 요약을 보기
df.describe(include=pd.np.object)
중복제거
df[""].unique() 중복되지 않은값 (독특한 값 )
df[" "].nunique() n을 앞에 붙이면 개수. 중복되지 않은 값의 개수

갯수- nunique()대신에 len() 을 써도 된다

그룹화된 요약값 -
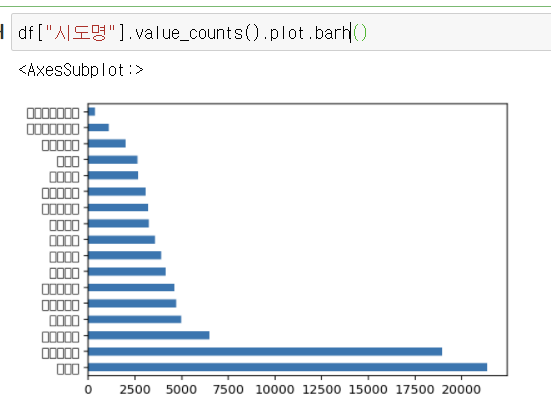
value_counts 를 사용하면 카테고리 형태의 데이터 갯수를 세어볼 수 있음
normalize=True 옵션을 사용하면 비율을 구할 수 있음

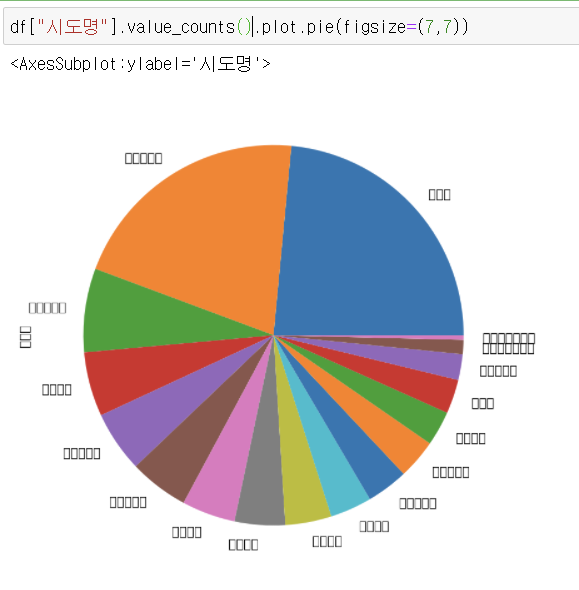
df["시도명"]. value_counts().plot.pie(figsize=(7,7))
seaborn이용

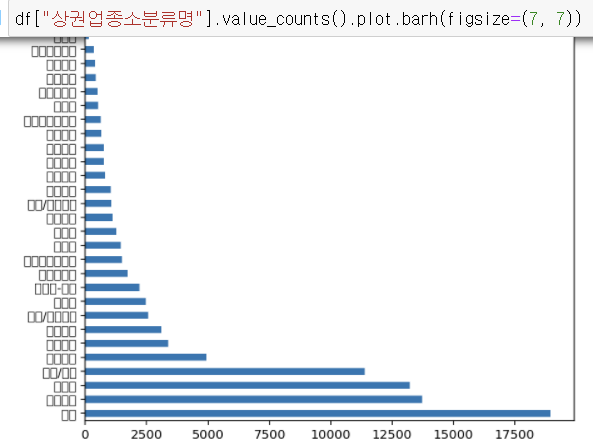
데이터색인하기
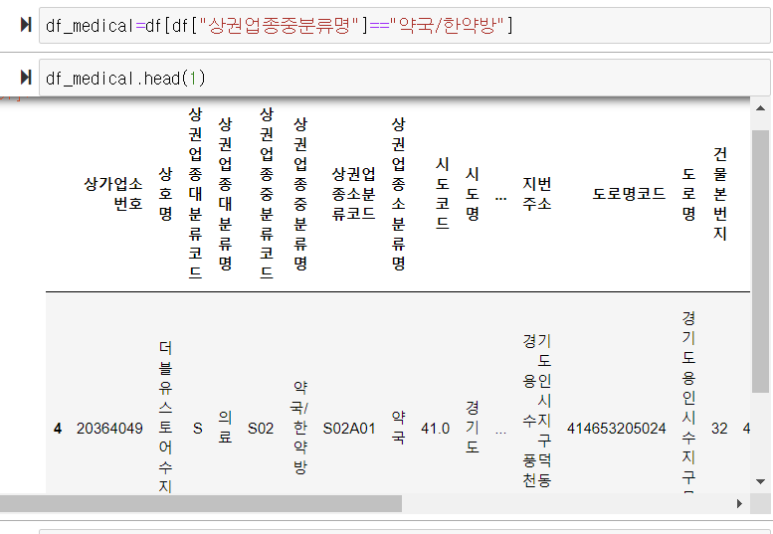
상권업종분류명이 약국, 한약방인 데이터를 가져와서 df_medical 변수에 담고 head로 미리보기
df_medi=df[df["상권업종중분류명"]== "유사의료업"]
df_medi["상호명"].value_counts().head(10)

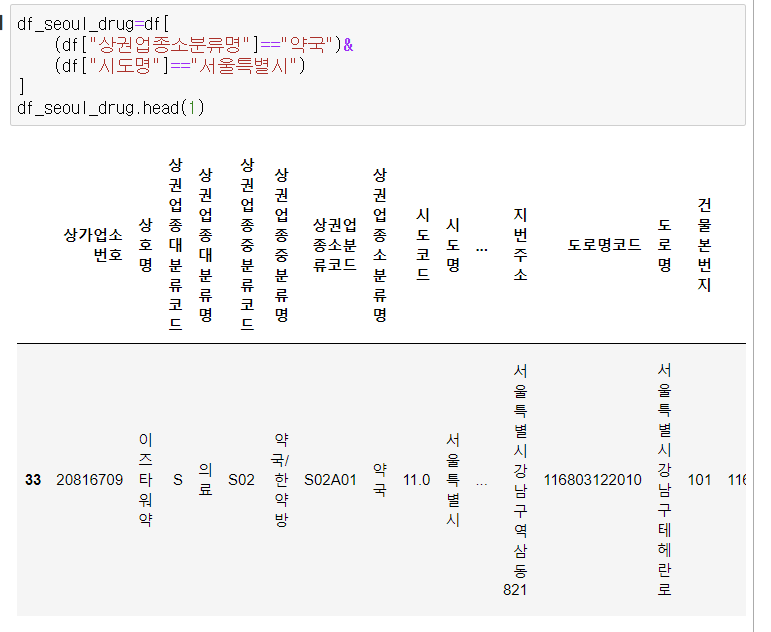
서울에 있는 약국
변수=df[ (df["상업업종소분류명" ]=="약국")&(df["시도명"]=="서울"])
]
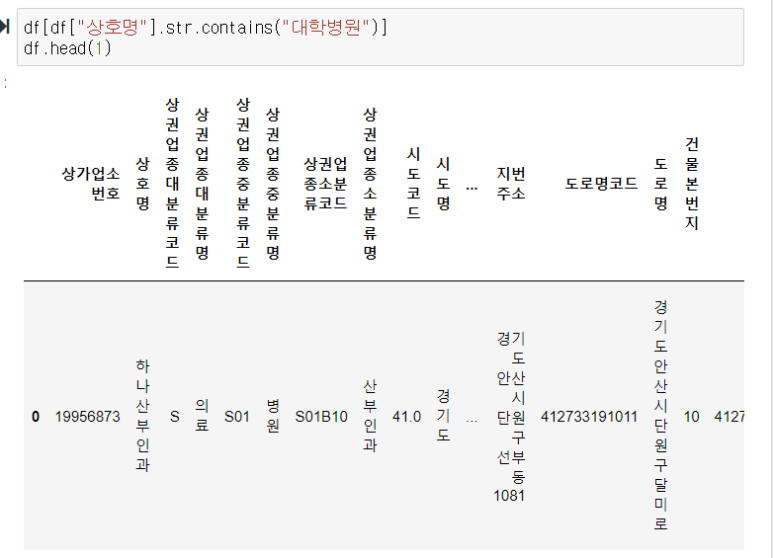
텍스트 데이터 색인
str.contain(" ") 사용
" " 이 들어가는지,
예)
상호명에 대학병원이 들어가는 것
df[df["상호명"].str.contains("대학병원")]
str.startswith(" ")
" "로 시작하는 것
서울로 시작하는 도로명주소
df[df["도로명주소"].str.startswith("서울")]

str.endswith(" ")
" "로 끝나는것

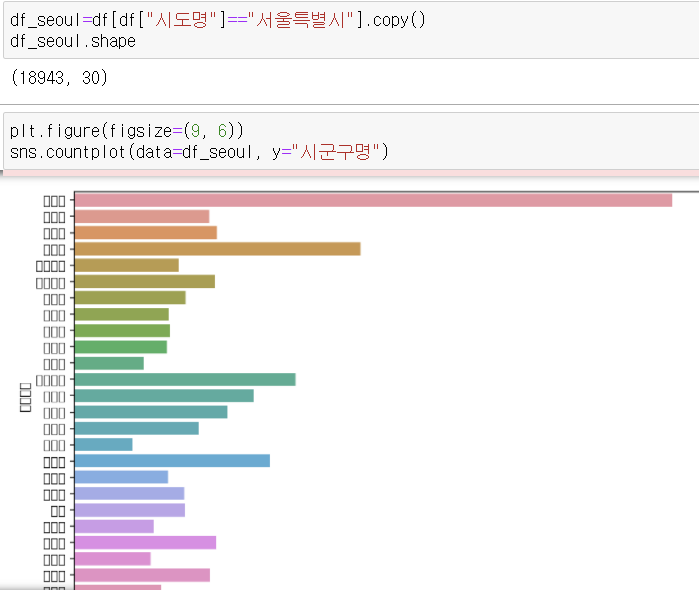
특정지역만 보기
seaborn의 countpolt을 사용하여 위에서 만든 df_seoul 데이터프레임의 시군구명을 시각화
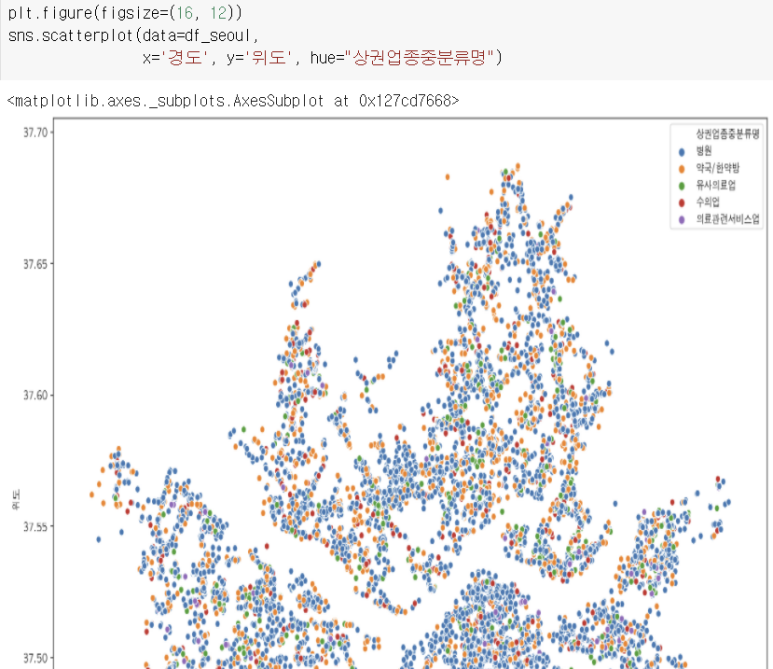
pandas -plot.scatter()로 경도, 위도 표시하기

seaborn - scatterplot
x, y에 대한 전체적인 분포를 확인하는 plot. (산점도)
데이터 그 자체가 퍼져있는 모양에 중점
hue는 컬러 구분 기준


folium





