
Jam's story
Pandas 3주차 본문
3째주 공부내용:
Pandas 기본사용법 + CCTV데이터 이용하여 구현해보기 (초반까지 밖에 못함 ) +pandas 복습
판다스(pandas) 기본 사용법 익히기 (dandyrilla.github.io)
이거 참고하면서 공부했습니다.
데이터 프레임 만들기 - > pd.DataFrame( index= , columns=)
index는 행 (세로 )
columns는 열 (가로)
DataFrame은 딕셔너리를 이용할 수있다.
데이터 프레임의 속성확인하기 - > dtypes
주피터로는 df2. +<TAB> 누르면 dtypes 이외에 다른 속성들도 같이 출력됨
데이터 확인하기
맨앞을 확인하기 -> df.head()
마지막을 확인하기 -> df.tail()
인덱스(행)을 확인하기 -> df.index
칼럼(가로)를 확인하기 -> df.columns
안에있는 numpy데이터를 확인하기 ->df.values
.describe()
생성했던 DataFrame 의 간단한 통계 정보를 보여줍니다. 컬럼별로 데이터의 개수(count), 데이터의 평균값(mean), 표준 편차(std), 최솟값(min), 4분위수(25%, 50%, 75%), 그리고 최댓값(max)들의 정보를 알 수 있습니다.
.T
열과 행을 바꾼다.
DataFrame 에서 index 와 column 을 바꾼 형태의 DataFrame 입니다.
.t()로 하면 에러 , 소문자로 해도 에러
.sort_index()
행과 열 이름을 정렬
axis=0 인덱스 기준 ( 기본값)
axis= 1 칼럼 기준
ascending=True는 오름차순,
ascending=False는 내림차순
.sort_values(by = ' ' )
B 칼럼에 대해 정렬한 결과
df['A'] = df.A
.loc
이름을 이용하여 선택하기 , 라벨의 이름을 이용하여 선택 가능
.iloc[ ]=.iat[ ]
인덱스 번호를 이용하여 데이터를 선택하기
df.iloc[3:5,0:2] ##인덱스가 3~4 && 칼럼 인덱스가 0~1
df.iloc[[1,2,4],[0,2]] ##인덱스가 1,2,4 && 칼럼인덱스가 0~1
##범위가 아닌 인덱스 숫자로 결정할때는 대괄호를 이용함
.isin()
조건을 설정하여 데이터 선택
E에서 값이 two, three 인것
택
데이터 특정 값 바꾸기
at[행, 열 ] == iat[행,열]
결측치
-비어있는 값은 Nan으로 채워짐
reindex
인덱스 변경/추가/삭제 , 복사된 데이터프레임을 반환
df1 = df.reindex(index=dates[0:4], columns=list(df.columns) + ['E'])
df1.loc[dates[0]:dates[1], 'E'] = 1
dropna()
결측치가 하나라도 존재하는 행들을 버리고 싶을 때
fillna()
만약 결측치가 있는 부분을 다른 값으로
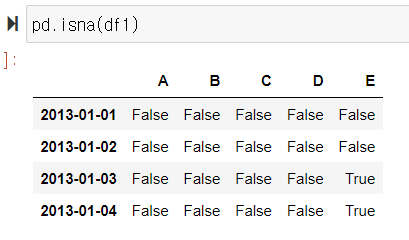
.isna()
결측치인지 아닌지 여부 판단
pd.isna(데이터프레임 이름 )
통계적 지표들
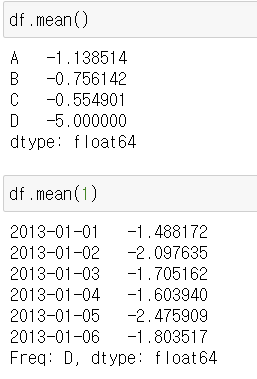
mean()
평균 구하기, 일반적으로 결측치는 제외하고 연산을 한다
mean(1)
인자로 1을 주게 면 컬럼이 아닌 인덱스 기준
결측치 계산
뭔소리인지 모르겟.
함수 적용하기
apply()
기존에 있던 함수를 넣어도 되고,
사용자 지정함수 lambda를 이용해도 된다.
히스토그램
values_counts()
데이터의 빈도 조사
합치기
concat
자료들을 이어 하나로 만들어줌
append
데이터 프레임에 하나의 행 추가
merge ()
데이터베이스 합치기
append()
데이터프레임의 맨 뒤에 행을 추가한다.
아래의 예제는 4번쨰 행을 기존 데이터 프레임의 맨 뒤에 한번 더 추가하는 방법을 보여줌
피벗테이블
시계열 데이터 다루기
1초마다 측정된 데이터를 5분마다 측정된 데이터의 형태로 바꾸고 싶을떄
범주형 데이터 다루기


plot
pandas에서 CSV 파일을 읽는 명령은 read_csv입니다.
그안에 한글을 사용하는 경우는 인코딩에 신경 써야 합니다.
CCTV 데이터는 UTF-8로 인코딩되어 있어서 read_csv 명령을 쓸 때 incoding 옵션에 UTF-8이라고 저장해야 합니다.
파일명지정= pd.read_csv('파일명' , encoding='utf-8')
이때 사용된 head() 명령은 pandas 데이터의 첫 5행만 보여달라는 것입니다.
. 데이터 뒤에 columns라고 하면 column의 이름들이 반환됩니다.
기관명 - >구별로 바꾸기
rename을 이용한다
rename(columns={CCTV_Seoul.columns[0]:'구별 ' }, replace=True)
CCTV_Seoul.columns[0] = '구별 ' 을 이용해 구별로 바꾸고
replace=True는 실제 CCTV_Seoul이라는 변수의 내용을 갱신하라는 의미 입니다.
CCTV 전체 개수인 소계로 정렬, 오름차순 (ascending=True)
CCTV의 전체 개수가 가장 작은 구는 '도봉구','마포구','송파구','중랑구','중구'라는 것을 알 수 있다
CCTV 최근 증가율
2016년 +2015년 +2014년을 더해 2013년 이전의 것으로 나눈후 * 100
최근증가율을 구한뒤 내림차순으로
CCTV 최근 증가율이 높은대로 정렬
그 결과를 보면 최근 3년간 CCTV가 그 이전 대비 많이 증가한 구는
'종로구','도봉구','마포구','노원구','강동구'라는 것도 알 수 있다.
엑셀파일 불러오기
여기서 오류가 났었는데, 파일명 앞에 r을 붙이라는 조언이 많았음
붙여도 안되어서 오류난 것을 검색하여, 블로그에 나와있는대로
xlrd 랑 openpyxl을 설치하니 바로 되었음
인덱스 0,1 줄이 이상함 그래서 중간에 header=2(인덱스 2부터 =3번쨰줄)추가해줌
칼럼의 이름 바꾸기= rename
CCTV_Seoul이라는 변수에는 '구별 CCTV 현황'을, pop_Seoul이라는 변수에는 '구별 인구 현황'을 저장
[Pandas 복습 ]
pandas의 데이터 유형 중 기초가 되는 것이 Series입니다.
대괄호로 만드는 파이썬의 list 데이터로 만들 수 있습니다.
중간에 NaN(Not A Number)도 넣었습니다.
6행 4열의 랜덤수들을 만든다. ->np.random.randn(6,4)
데이터잘라서 보기
index 하고 () 이 괄호를 쓰는게 아니라 딱 index,
범위를 지정하고 싶으면 [a:b] 대괄호 사용
info() 명령을 사용하면 데이터 프레임의 개요를 알수있다.
df.describe()
describe 명령어는 통계적 개요를 확인 할 수 있습니다.
개수와 평균 뿐만 안니라 min,max와 각 1/4 지점,표준편차까지 한번에 알 수 있습니다.
by로 지정하여 ,내림차순으로
ascending =True, (오름차순)
ascending =False (내림차순)
df변수에서 좀 더 통계 느낌의 데이터를 볼 때는 특정 함수를 적용시키면 좋습니다.
이때 사용하는 것이 apply 명렁입니다.
누적합을 알고 싶을 때는 numpy의 cumsum을 이용하면 됩니다.
다음주까지 공부 할 것 :
pandas 복습+ CCTV 현황,인구현황 이어서



