
Jam's story
[Oracle] days 09 본문
아침쪽지시험
1. PIVOT() 함수의 형식을 적으세요.
SELECT *
FROM (피벗 대상 쿼리문)
PIVOT (그룹함수(집계컬럼) FOR 피벗컬럼 IN(피벗컬럼 값 AS 별칭...))
2. emp 테이블의 각 JOB별 사원수 (피봇)
select *
from (select job from emp)
pivot (count(job) for job in ( 'CLERK' ,' SALESMAN', 'PRESIDENT', ' MANAGER', 'ANALYST'));
--pivot( for in ()) 이렇게 잡아놓고 쓰면편하다
CLERK SALESMAN PRESIDENT MANAGER ANALYST
---------- ---------- ---------- ---------- ----------
3 4 1 3 1
3. emp 테이블에서 [JOB별로] 각 월별 입사한 사원의 수를 조회
ㄱ. COUNT(), DECODE() 사용
select hiredae
,to_char(hiredate,'mm') --문자형태
,extract(month from hiredate) --숫자형태
from emp ;
select job, count(*)
,count(decode(exract(month from hiredate),1,'o'))"1월"
,count(decode(exract(month from hiredate),2,'o'))"1월"
,count(decode(exract(month from hiredate),3,'o'))"1월"
,count(decode(exract(month from hiredate),4,'o'))"1월"
,count(decode(exract(month from hiredate),5,'o'))"1월"
,count(decode(exract(month from hiredate),6,'o'))"1월"
,count(decode(exract(month from hiredate),7,'o'))"1월"
,count(decode(exract(month from hiredate),8,'o'))"1월"
from emp
group by job;
select job, count(*),
count(decode( to_char(hiredate, 'mm'), '01', 'O')) "01월"
, count(decode( to_char(hiredate, 'mm'), '02', 'O')) "02월"
, count(decode( to_char(hiredate, 'mm'), '03', 'O')) "03월"
, count(decode( to_char(hiredate, 'mm'), '04', 'O')) "04월"
, count(decode( to_char(hiredate, 'mm'), '05', 'O')) "05월"
, count(decode( to_char(hiredate, 'mm'), '06', 'O')) "06월"
, count(decode( to_char(hiredate, 'mm'), '07', 'O')) "07월"
, count(decode( to_char(hiredate, 'mm'), '08', 'O')) "08월"
, count(decode( to_char(hiredate, 'mm'), '09', 'O')) "09월"
, count(decode( to_char(hiredate, 'mm'), '10', 'O')) "10월"
, count(decode( to_char(hiredate, 'mm'), '11', 'O')) "11월"
, count(decode( to_char(hiredate, 'mm'), '12', 'O')) "12월"
from emp
group by job;
JOB COUNT(*) 1월 2월 3월 4월 5월 6월 7월 8월 9월 10월 11월 12월
--------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ----------
CLERK 3 1 0 0 0 0 0 0 0 0 0 0 2
SALESMAN 4 0 2 0 0 0 0 0 0 2 0 0 0
PRESIDENT 1 0 0 0 0 0 0 0 0 0 0 1 0
MANAGER 3 0 0 0 1 1 1 0 0 0 0 0 0
ANALYST 1 0 0 0 0 0 0 0 0 0 0 0 1
ㄴ. GROUP BY 절 사용
select extract(month from hiredate)"월"
,count(*)"인원수"
from emp
group by extract(month from hiredate)
order by extract(month from hiredate) asc;
월 인원수
---------- ----------
1 1
2 2
4 1
5 1
6 1
9 2
11 1
12 3
8개 행이 선택되었습니다.
ㄷ. PIVOT() 사용
select
from (select job,extract(month from hiredate)hire_month from emp)
pivot( count(*) for hire_date in (1,2,3,4,5,6,7,8,9,10,11,12));
select extract(month from hiredate)hire_month
from emp;
select *
from(
select
extract( month from hiredate) month
from emp
)
pivot (count(month) for month in(1,2,3,4,5,6,7,8,9,10,11,12) );
JOB 1월 2 3 4 5 6 7 8 9 10 11 12
--------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ----------
CLERK 1 0 0 0 0 0 0 0 0 0 0 2
SALESMAN 0 2 0 0 0 0 0 0 2 0 0 0
PRESIDENT 0 0 0 0 0 0 0 0 0 0 1 0
MANAGER 0 0 0 1 1 1 0 0 0 0 0 0
ANALYST 0 0 0 0 0 0 0 0 0 0 0 1
4. emp 테이블에서 각 부서별 급여 많이 받는 사원 2명씩 출력
실행결과)
SEQ EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ---------- ---------- --------- ---------- -------- ---------- ---------- ----------
1 7839 KING PRESIDENT 81/11/17 5000 10
2 7782 CLARK MANAGER 7839 81/06/09 2450 10
1 7902 FORD ANALYST 7566 81/12/03 3000 20
2 7566 JONES MANAGER 7839 81/04/02 2975 20
1 7698 BLAKE MANAGER 7839 81/05/01 2850 30
2 7654 MARTIN SALESMAN 7698 81/09/28 1250 1400 30
-rank 순위함수 partition 옵션으로 그룹
-top-n 방식
--from keyword 오류 나서, select * -> select emp.*
select dept_rank seq, t.empno, t.ename,t.sal
from (select emp.*, rank() over(partition by deptno order by sal desc) dept_rank
from emp)t
where dept_rank<=2
select rownum, t.*
from (
select *
from emp
order by sal desc
)t
where rownum<=2;
----------------------------
emp 테이블에서 grade 등급별 사원수 조회
- count() , decode()
--decode에서 'o'처럼 값을 주지 않으면 null값이 됨
select
count(decode(등급,1,'o'))
1) 먼저 이렇게 만들어놓고
select ename, sal, losal ||'~' ||hisal, grade
from emp e, salgrade s
where e.sal between s.losal and s.hisal;
2)
select count(*)
,count(decode(grade , 1,'o') )"1등급"
,count(decode(grade , 2,'o') )"2등급"
,count(decode(grade ,3,'o') )"3등급"
,count(decode(grade ,4,'o') )"4등급"
,count(decode(grade ,5,'o') )"5등급"
from emp e, salgrade s
where e.sal between s.losal and s.hisal;
--식별자(별칭포함 )명명할때 숫자로 시작하면 안되기 때문에 ""를 넣어야한다.- group by
select grade || '등급' , count(*) 사원수
from emp e, salgrade s
where e.sal between s.losal and s.hisal
group by grade
order by grade asc;- pivot()
select *
from(select grade
from emp e, salgrade s
where e.sal between s.losal and s.hisal)
pivot(count(*) for grade in (1 as"1등급",2 as"2등급",3 as "3등급",4 as "4등급",5 as "5등급"));
select *
from(select deptno, grade
from emp e, salgrade s
where e.sal between s.losal and s.hisal)
pivot(count(*) for grade in (1 as"1등급",2 as"2등급",3 as "3등급",4 as "4등급",5 as "5등급"));
pivot(for in (목록)) --목록에 쿼리 넣으면 안된다.
emp 테이블에서 년도별 입사사원수 조회
- count() decode()
select
count(decode(to_char(hiredate,'yyyy'),1980,'o')) "1980년"
,count(decode(to_char(hiredate,'yyyy'),1981,'o')) "1981년"
,count(decode(to_char(hiredate,'yyyy'),1982,'o')) "1982년"
from emp- group by
select extract(year from hiredate)"year", count(*)
from emp
group by extract(year from hiredate)
order by extract(year from hiredate) asc;- pivot
select *
from(
select
extract( year from hiredate) year
from emp
)
pivot (count(year) for year in(1980, 1981, 1982) );
테이블 생성
create table tbl_pivot(
--not null은 필수 입력
no number not null primary key -- ()괄호안쓰면 최대로 잡힘,기본키 설정
, name varchar2(20) not null --한글은 varchar2 6글자까지 저장가능
,jumsu number(3) --최대가 100이니까 정수3자리까지 가능
);
--학생의 정보추가
--insert into 테이블명(칼럼명) values(해당 값들 ) ;
--문제점: 여러 과목의 점수를 넣어야한다. 국어 영어 수학
insert into tbl_pivot(no,name,jumsu) values(1,'박예린',90);
insert into tbl_pivot(no,name,jumsu) values(2,'박예린',45);
insert into tbl_pivot(no,name,jumsu) values(3,'박예린',90);
insert into tbl_pivot(no,name,jumsu) values(4,'안시은',56);
insert into tbl_pivot(no,name,jumsu) values(5,'안시은',45);
insert into tbl_pivot(no,name,jumsu) values(6,'안시은',12);
insert into tbl_pivot(no,name,jumsu) values(5,'김민',99);
insert into tbl_pivot(no,name,jumsu) values(6,'김민',85);
insert into tbl_pivot(no,name,jumsu) values(7,'김민',100);
commit;
select *
from tbl_pivot;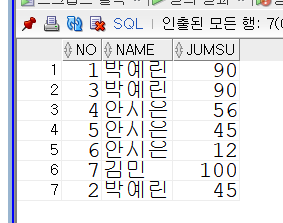
pivot을 통해 가로 세로 변환
--피벗시켜서 가로로 출력
--테이블을 수정하는게 맞지만, no를 3으로나눠서 정리
select trunc((no-1)/3)+1 no,name,jumsu
,decode(mod(no,3),1,'국어',2,'영어',0,'수학')subject
from tbl_pivot
order by no asc;
select no
,trunc((no-1)3)+1
from tbl_pivot;
--여기서 부터
select *
from (select trunc((no-1)/3)+1 no,name,jumsu
,decode(mod(no,3),1,'국어',2,'영어',0,'수학')subject
from tbl_pivot)
pivot ( max(jumsu) for subject in ('국어','영어','수학') )
order by no asc;
랜덤: dbms.random()
자바의 0.0<=math.random <1.0
자바의 패키지 개념이랑 다르다.
pl/sql 확장된 sql+pl(절차적언어)
| dbms_random.value(0,100) | 0<=x<100 |
| dbms_random.string('u',개수) | 대문자 |
| dbms_random.string('l', 개수) | 소문자 |
| dbms_random.string('a', 개수) | 알파벳 대소문자 |
| dbms_random.string('p', 개수) | 특수문자 |
| dbms_random.string('x', 개수) | 대문자+숫자 |
select
--dbms_random.value
--,dbms_random.value(0,100) 0<=x<100
--,dbms_random.value(0,45)
--,floor(dbms_random.value)+1 1~45깂
dbms_random.string('u',5) --u는 upper
,dbms_random.string('l',5)--ㅣ은 lower
,dbms_random.string('a',5)--a는 알파벳
,dbms_random.string('x',5) --대문자+숫자 5개
,dbms_random.string('p',5) --특수문자
from dual;- 150<=정수<=200 출력쿼리
select floor(dbms_random.value(0,51))+150
from dual;
select dbms_random.value
,trunc(dbms_random.value*51) +150
,trunc(dbms_random.value(0,51))+150
,trunc(dbms_random.value(150,201))
from dual;
데이터타입
char
고정길이 문자자료형
1byte ~2000byte 알파벳(1문자=1byte),한글(1문자=3byte)
char(size [byte|char])
char(3) ==char(3 byte)
char(3 byte) ==3문자
char
ㄹ.테스트
create table tbl_char(
aa char
,bb char(3)
,cc char(3 char)
);
select *
from tbl_char;
insert into tbl_char(aa,bb,cc) values('a','kbs','kbs');
insert into tbl_char(aa,bb,cc) values('b','k','캐비어');
nchar==n +char ==unicode+char
ㄱ.유니코드 모든 언어의 1문자를 2바이트로 처리
ㄴ. 형식
ㄷ.nchar[(size)]
ㄹ.고정길이 최대2000바이트
ㅁ.nchar==nchar(1)
ㅂ.nchar(5)
create table tbl_nchar(
aa char
,bb char(3 char)
,cc nchar(3)
);
insert into tbl_nchar values('a','홍길x','홍길동');
select *
from tbl_nchar;
varchar2=var+char
ㄱ.가변길이 최대 4000바이트
ㄴ.형식 varchar2(size[byte|char]) 의 시노님 varchar
ㄷ.char==char(1 byt) varchar2==varchar2(4000 byte)
varchar2== varchar2(4000 byte)
varchar2(10)==varchar2(10 byte)
varchar2(10 char)
고정길이/ 가변길이 차이점
char=고정길이
varchar=가변길이
'kbs'저장
char [k][b][s][][][][[][][][][]
varchar [k][b][s]
고정길이: 모든 값의 길이가 같을때 -예)주민등록번호
가변길이: 길이가 다 다른 값 -예) 제목
nvarchar2(size)
n은 모든문자 똑같은 바이트로 저장한다는뜻
n(유니코드)+var(가변길이)+char(문자열)
최대 4000바이트
nvarchar2[(size)]
nvarchar2==nvarchar2(최대값)
long
가변길이의 문자자료형 /2gb
number([p],[s])
ㄱ.숫자(정수, 실수)
ㄴ.precision 정확==전체자릿수 1~38
, scale 규모(정밀)==소수점 이하 자릿수 -84~127 의 줄임말
ㄷ.number(p)정수, number(p,s)실수
ㄹ.number == number(38,127)

create table tbl_number(
kor number(3)
,eng number(3)
,mat number(3)
,tot number(3)
,avgs number(5,2)
);
insert into tbl_number (kor,eng,mat) values(90,85,100);
insert into tbl_number (kor,eng,mat) values(90,85,101);
insert into tbl_number (kor,eng,mat) values(90,85,-1);
commit;
select *
from tbl_number;
-- value larger than specified precision allowed for this column
--지정된 크기보다 너무 크다.
insert into tbl_number (kor,eng,mat) values(90,85,1001);
update tbl_number
set kor=trunc(dbms_random.value(0,101))
, eng=trunc(dbms_ramdom.value(0,101))
, mat=trunc(dbms_random.value(0,101))
;
update tbl_number
set tot=kor+eng+mat
, avgs=(kor+eng+mat)/3;
commit;
update tbl_number
set avgs=89.23;
update tbl_number
set avgs=999.877;
set avgs=89.342999;
set avgs=99999; --value larger than specified precision allowed for this column
number(5,2)인데
update tbl_number set avgs=99999; 는 오류가 난다.
소수점 2자리는 무조건 있어야 하는데, 999.00 이기 때문에 1000이하로만 저장이 가능하다
date
-세기, 년 ,월, 일 ,+시,+분 ,초 를 저장하는 자료형 고정길이 7바이트 저장
학생 정보를 저장하는 테이블 tbl_number
칼럼:
학번 number(p,s) number(7) -1111111~1111111
이름 number(3) -999~999 0<= <=100
국어 number(3) char , nchar, varchar2, nvarchar2 ,가변길이 varchar2(size BYTE|CHAR)
영어 number(3) varchar2(20)
수학 number(3) 0~300
총점 number(3)
평균 number(3)
등수 number(3)
생일 date
주민번호 char(14)
기타 long
timestamp(n) date의 확장된 자료형 , 초/00000000 나노초까지 나타냄
timestamp==timestamp(6)
interval year[(n)] to month n=2
interval day[(n1)] to second
raw()
long raw
이미지 파일-> 테이블의 어떤 컬럼
test.gif img raw/long raw
lob(larger object)
ㄱ.b+lob=blob
ㄴ.c+lob=clob
ㄷ.n+c+lob=nclob (유니코드 텍스트 데이터)
텍스트 long, 이미지, 이진데이터 (long raw)+2gb 이상 (대용량) lob
row id =테이블 내의 행의 고유 주소를 가지는 64 문자 타입
--오라클 자료형 정리--
날짜 -date, timestamp(n)-[초의 나노까지 나타냄]
숫자- number(p,s) , float(p) x
문자-char, nchar
varchar2==varchar, nvarchar2
long(2gb)
2진데이터 =raw, long raw
----file----
blob Binary 데이터를 4GB까지 저장 (4GB= (232 -1바이트))
clob Binary 데이터를 4GB까지 저장 (4GB= (232 -1바이트))
nclob Binary 데이터를 4GB까지 저장 (4GB= (232 -1바이트))
bfile 테이블 내의 행의 고유 주소를 가지는 64 문자 타입
count
쿼리한 행의 수를 반환한다.
COUNT(컬럼명) 함수는 NULL이 아닌 행의 수를 출력하고 COUNT(*) 함수는 NULL을 포함한 행의 수를 출력한다.
【형식】
COUNT([* ¦ DISTINCT ¦ ALL] 컬럼명) [ [OVER] (analytic 절)] 질의한 행의 누적된 값 반환
select name, basicpay
, count(*) over (order by basicpay asc)
from insa;
select buseo, name, basicpay,count(*) over(partition by buseo order by basicpay desc)
from insa;
sum
형식
SUM ([DISTINCT ¦ ALL] expr)
[OVER (analytic_clause)]
select distinct buseo
,sum(basicpay ) over(order by buseo) ps
from insa
order by ps asc;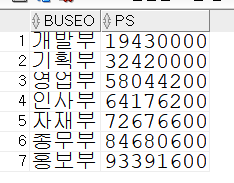
avg
【형식】
AVG( [DISTINCT ¦ ALL] 컬럼명) [ [OVER] (analytic 절)]
--지역평균급여 차
select buseo,name, basicpay, avg(basicpay) over (order by city)
from insa;
select avg(basicpay)
from insa
where city='경기';
테이블 생성
create table scott.tbl_member(
id varchar2(10) not null primary key
,name varchar2(20) not null
,age number(3)
,birth date
);테이블 삭제
drop table tbl_member;테이블 구조
desc tbl_member;테이블변경- 칼럼추가
【형식】컬럼추가
ALTER TABLE 테이블명
ADD (컬럼명 datatype [DEFAULT 값]
[,컬럼명 datatype]...);
【형식】constraint추가
ALTER TABLE 테이블명
ADD (컬럼명 datatype CONSTRAINT constraint명 constraint실제값
[,컬럼명 datatype]...);
• 한번의 add 명령으로 여러 개의 컬럼 추가가 가능하고, 하나의 컬럼만 추가하는 경우에는 괄호를 생략해도 된다.
• 추가된 컬럼은 테이블의 마지막 부분에 생성되며 사용자가 컬럼의 위치를 지정할 수 없다
• 추가된 컬럼에도 기본 값을 지정할 수 있다.
• 기존 데이터가 존재하면 추가된 컬럼 값은 NULL로 입력 되고, 새로 입력되는 데이터에 대해서만 기본 값이 적용된다.
alter table tbl_member
add(
tel char(13) not null
,etc varchar2(200)
);
desc tbl_member;
칼럼 수정

modify 명령은 테이블의 컬럼을 변경하고자 할 때 사용한다.
【형식】
ALTER TABLE 테이블명
MODIFY (컬럼명 datatype [DEFAULT 값]
[,컬럼명 datatype]...);
• 데이터의 type, size, default 값을 변경할 수 있다.
• 변경 대상 컬럼에 데이터가 없거나 null 값만 존재할 경우에는 size를 줄일 수 있다.
• 데이터 타입의 변경은 CHAR와 VARCHAR2 상호간의 변경만 가능하다.
• 컬럼 크기의 변경은 저장된 데이터의 크기보다 같거나 클 경우에만 가능하다.
• NOT NULL 컬럼인 경우에는 size의 확대만 가능하다.
• 컬럼의 기본값 변경은 그 이후에 삽입(insert)되는 행부터 영향을 준다.
• 컬럼이름의 직접적인 변경은 불가능하다.
• 컬럼이름의 변경은 서브쿼리를 통한 테이블 생성시 alias를 이용하여 변경이 가능하다.
• alter table ... modify를 이용하여 constraint=제약조건을 수정할 수 없다.
- etc varchar2(200) 칼럼의 크기를 255로 수정 - 칼럼 크기 수정
alter table tbl_member
modify(etc varchar2(255));
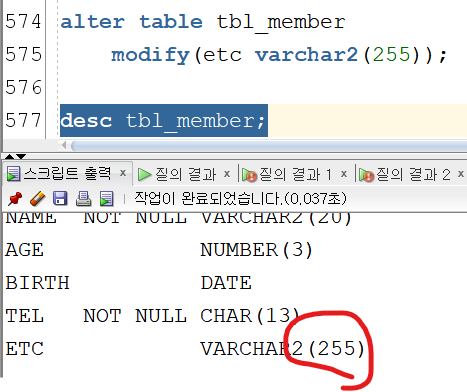
- etc 칼럼명을 bigo 칼럼명으로 수정- 칼럼 이름 수정 , 칼럼명 수정
alter table tbl_member
rename column etc to bigo;
칼럼삭제
복구안됨
alter table ... drop 문은 테이블을 삭제하는 것이 아니라, 특정 테이블의 컬럼이나 constraint를 삭제할 때 사용한다.
【형식】
ALTER TABLE 테이블명
DROP COLUMN 컬럼명;
alter table tbl_member
drop column bigo;
테이블 이름 수정
tbl_member 테이블의 이름 수정 (tbl_customer )
rename tbl_member to tbl_customer ;
'Oracle' 카테고리의 다른 글
| [Oracle ]days12 - join (0) | 2022.04.19 |
|---|---|
| [Oracle] days11 (0) | 2022.04.18 |
| [Oracle] 달력만들기 (0) | 2022.04.18 |
| SQL funtion (0) | 2022.04.17 |
| [Oracle] days10 (0) | 2022.04.15 |

