
Jam's story
[Oracle] days11 본문
쪽지시험
1. truncate / delete / drop 대해서 설명하세요
truncate 테이블 삭제, 자동커밋 롤백불가
delete 테이블데이터삭제, where 조건문이 없으면 전체데이터를 삭제
drop 테이블 자체를 삭제
2. insert 문 수행 중 다음과 같은 오류가 발생했다면 이유에 대해 설명하세요
ㄱ. 00947. 00000 - "not enough values"
insert into 테이블명(칼럼명 갯수) values (칼럼명 )
충분한 값이 아니다.
ㄴ. ORA-00001: unique constraint (SCOTT.SYS_C007770) violated 고유키위배
ㄷ. ORA-02291: integrity constraint (SCOTT.FK_DEPTNO) violated - parent key not found
부모키를 찾을 수 없음
3. 서브쿼리를 사용해서 테이블 생성
ㄱ. deptno, dname, empno, ename, sal+nvl(comm,0) pay, grade 컬럼을 가진 새로운 테이블 생성
ㄴ. 테이블명 : tbl_empdeptgrade
create table tbl_empdeptgrade
as(
select deptno, dnam, empno, ename, sal+nvl(comm,0) pay, grade
from dept d join emp e on d.deptno=e.deptno
join salgrade s on e.,sal between s.losal and s.hisal
);
4-1. insa 테이블에서 num, name 가져와서 tbl_score 테이블 생성
create table tbl_score
as(
select num,name
from insa
);
4-2. kor, eng, mat, tot , avg , grade, rank 컬럼 추가
alter table tbl_score
add(
kor number(3) default 0
,ent numbe(3) default 0
,mat number(3) default 0
,tot number(3)
,avg number(5,2)
,grade char(1 char)
,rank number
);
4-3. 각 학생들의 kor,eng,mat 점수 0~100 랜덤하게 채워넣기.
update tbl_score
set kor=trunc(dbms_random.value(0,101)),
eng=trunc(dbms_random.value(0,101)),
mat=trunc(dbms_random.value(0,101));
4-4. 총점, 평균, 등급, 등수 수정
조건)
등급은 모든 과목이 40점이상이고, 평균 60 이상이면 "합격"
평균 60 이상이라도 한 과목이라 40점 미만이라면 "과락"
그외는 "불합격" 이라고 저장.
update tbl_score
set avg= (kor+eng+mat)/3
,grade= case
when kor>=40 and eng>=40 and mat >=40 and avg>=60 then '합격'
when kor<=40 or eng<=40 or mat <=40 and avg>=60then '과락'
else '불합격 '
end;
5. emp 테이블의 구조를 확인하고, 제약조건을 확인하고, 임의의 사원 정보를 추가하는 INSERT 문을 작성하세요.
ㄱ. 구조확인 쿼리 desc emp;
ㄴ. 제약조건 확인 쿼리
select *
from tabs;
from user_constriants;
from user_tables;
where table_name=upper('emp');
ㄷ. INSERT 쿼리
insert into emp values('값들' );
6-1. emp 테이블의 구조만 복사해서 새로운 tbl_emp10, tbl_emp20, tbl_emp30, tbl_emp40 테이블을 생성하세요.
create table tbl_emp10 as select * from emp where 1=0 ;
create table tbl_emp20 as select * from emp where 1=0 ;
create table tbl_emp30 as select * from emp where 1=0 ;
create table tbl_emp40 as select * from emp where 1=0 ;
6-2. emp 테이블의 각 부서에 해당하는 사원정보를 위에서 생성한 테이블에 INSERT 하는 쿼리를 작성하세요.
insert first
when deptno=10 then
into emp_10 values(emp,ename, job,mgr, hiredate ,sal, comm, deptno)
when deptno=20 then
into emp_20 values(emp,ename, job,mgr, hiredate ,sal, comm, deptno)
when deptno=30 then
into emp_30 values(emp,ename, job,mgr, hiredate ,sal, comm, deptno)
when deptno=40 then
into emp_40 values(emp,ename, job,mgr, hiredate ,sal, comm, deptno)
select * from emp ;
7. 조건이 있는 다중 INSERT 문에서 INSERT ALL 과 INSERT FIRST 문에 대한 차이점을 설명하세요.
insert first는 맞는 조건 하나 만나면, 그다음 조건문은 실행하지않음
여자학생들만 영어점수5점추가
UPDATE tbl_score
SET eng = eng + 5
-- 1003 , 1005
WHERE num = ANY ( --하나라도 만족하는 값이 있으면 결과를 리턴
SELECT num
FROM insa
WHERE MOD(SUBSTR(ssn, -7, 1), 2) = 0 AND num <= 1005
);--1005번보다 작은 여자학생중 여자만 데려와서계층구조-level
답변형 게시판을 구현할때 계층적 질의 사용
게시글 글번호 empno, 부모게시글번호 mgr
dbms 오라클에서만 사용할 수 있다.
【참조】테이블에서 행(row)의 LEVEL(레벨)를 가리키는 일련번호 순서
[LEVEL 함수]
ㄱ. CONNECT_BY_ISLEAF 더 이상 LEAF 데이터가 없으면 1, 있으면 0을 반환
ㄴ. CONNECT_BY_ISCYCLE root 데이터이면 1, 아니면 0을 반환
ㄷ. CONNECT_BY_ROOT 각 데이터의 root값과 LEVEL 값을 반환
select empno, ename, mgr , level
from emp
--startwith -> 최상위노드 mgr 없는 사원
start with mgr is null
connect by prior empno=mgr; --자식을 왼쪽 부모를 오른쪽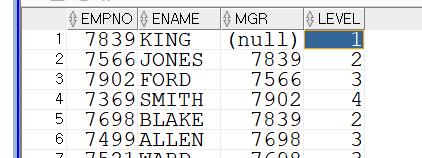
ㄷ. 【형식】
SELECT [LEVEL] {*,컬럼명 [alias],...}
FROM 테이블명
WHERE 조건
START WITH 조건
CONNECT BY [PRIOR 컬럼1명 비교연산자 컬럼2명]
또는
[컬럼1명 비교연산자 PRIOR 컬럼2명]
ㄹ. PRIOR 위치 : TOP-DOWN 방식, BOTTOM-UP 방식
TOP-DOWN방식 PRIOR 자식키 = 부모키
계층구조 한눈에 파악 출력
select lpad(' ',3*level-3) || ename
,empno,mgr,level
from emp
start with mgr is null
connect by prior empno=mgr;
select lpad(' ',3*level-3) || ename
,empno,mgr,level
,sys_connect_by_path(ename,'/')path
,connect_by_root ename root_node --최상의 루트노드
,connect_by_isleaf
from emp
start with mgr is null
connect by prior empno=mgr;
tbl_level 테이블 만들기
create table tbl_level(
deptno number(3) not null primary key,
dname varchar2(30) not null,
college number(3),
loc varchar2(10)
);
-- Table TBL_LEVEL이(가) 생성되었습니다.
insert into tbl_level ( deptno, dname, college, loc ) values ( 10,'공과대학', null , null);
insert into tbl_level ( deptno, dname, college, loc ) values ( 100,'정보미디어학부',10, null );
insert into tbl_level ( deptno, dname, college, loc ) values ( 101,'컴퓨터공학과',100,'1호관');
insert into tbl_level ( deptno, dname, college, loc ) values ( 102,'멀티미디어학과',100,'2호관');
insert into tbl_level ( deptno, dname, college, loc ) values ( 200,'메카트로닉스학부', 10,null);
insert into tbl_level ( deptno, dname, college, loc ) values ( 201,'전자공학과',200,'3호관');
insert into tbl_level ( deptno, dname, college, loc ) values ( 202,'기계공학과',200,'4호관');
SELECT *
FROM tbl_level;
ROLLBACK;
COMMIT;SELECT LPAD( ' ', (LEVEL-1)*3 ) || dname 조직도
, deptno, college, level
FROM tbl_level
START WITH deptno = 10
CONNECT BY PRIOR deptno = college ; -- TOP-DOWN 방식
정보미디어학부 가지를 삭제
SELECT LPAD( ' ', (LEVEL-1)*3 ) || dname 조직도
, deptno, college, level
FROM tbl_level
WHERE dname != '정보미디어학부'
START WITH deptno = 10
CONNECT BY PRIOR deptno = college ; -- TOP-DOWN 방식
-- 정보미디어학부 + 하위(자식) 가지도 삭제 : CONNECT BY 절 사용.
SELECT LPAD( ' ', (LEVEL-1)*3 ) || dname 조직도
, deptno, college, level
FROM tbl_level
-- WHERE dname != '정보미디어학부'
START WITH deptno = 10
CONNECT BY PRIOR deptno = college AND dname != '정보미디어학부' ; -- TOP-DOWN 방식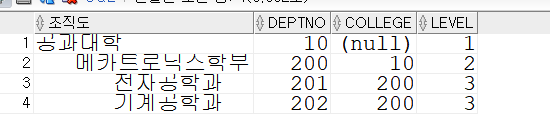
merge(병합, 통합)
ㄱ. "구조가 같은" 두 개의 테이블을 비교하여
-> 하나의 테이블로 합치기 위한 데이터 조작이다
ㄴ. UNION, UNION ALL 차이점 ? A U B
ㄷ. 사용하는 곳 ? A <- B
하루에 수만건씩 발생하는 데이터를 하나의 테이블에 관리할 경우 대량의 데이터로 인해 질의문의 성능이 저하된다.
이런 경우, 지점별로 별도의 테이블에서 관리하다가 년말에 종합 분석을 위해 하나의 테이블로 합칠 때 merge 문을 사용하면 편리하다.
ㄹ. merge하고자 하는 소스 테이블의 행을 읽어 타킷
테이블에 매치되는 행이 존재하면 새로운 값으로 UPDATE를 수행하고,
만일 매치되는 행이 없을 경우 새로운 행을 타킷 테이블에서 INSERT를 수행한다.
【형식】
MERGE [hint] INTO [schema.] {table ¦ view} [t_alias]
USING {{[schema.] {table ¦ view}} ¦
subquery} [t_alias]
ON (condition) [merge_update_clause] [merge_insert_clause] [error_logging_clause];
【merge_update_clause 형식】
WHEN MATCHED THEN UPDATE SET {column = {expr ¦ DEFAULT},...}
[where_clause] [DELETE where_clause]
【merge_insert_clause 형식】
WHEN NOT MATCHED THEN INSERT [(column,...)]
VALUES ({expr,... ¦ DEFAULT}) [where_clause]
【where_clause 형식】
WHERE condition
【error_logging_clause 형식】
LOG ERROR [INTO [schema.] table] [(simple_expression)]
[REJECT LIMIT {integer ¦ UNLIMITED}]
merge 문제
CREATE TABLE tbl_merge1
(
id number primary key
, name varchar2(20)
, pay number
, sudang number
);
CREATE TABLE tbl_merge2
(
id number primary key
, sudang number
);
INSERT INTO TBL_merge1 (id, name, pay, sudang) VALUES (1, 'a', 100, 10);
INSERT INTO TBL_merge1 (id, name, pay, sudang) VALUES (2, 'b', 150, 20);
INSERT INTO TBL_merge1 (id, name, pay, sudang) VALUES (3, 'c', 130, 0);
INSERT INTO TBL_merge2 (id, sudang) VALUES (2,5);
INSERT INTO TBL_merge2 (id, sudang) VALUES (3,10);
INSERT INTO TBL_merge2(id, sudang) VALUES (4,20);
COMMIT;
select * from tbl_merge1;
select * from tbl_merge2;tbl_merge1
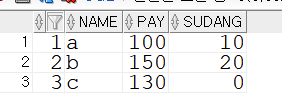
tbl_merge2

merge into tbl_merge2 t2
using (select id, sudang from tbl_merge1 )t1
on(t1.id=t2.id )
when matched then --일치하면 update
update set t2.sudang=t2.sudang+t1.sudang
when not matched then --일치하지 않으면 insert
insert (t2.id, t2.sudang) values (t1.id, t1.sudang);tbl_merge2
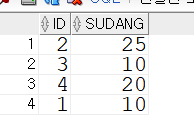
제약조건
테이블에 부여된 제약조건의 관계키는 user_constraints 뷰를 사용하여 확인할 수 있다.
제약조건은 data integrity(데이터 무결성)을 위하여 주로 테이블에 행(row)을 입력, 수정, 삭제할 때 적용되는 규칙으로 사용되며 테이블에 의해 참조되고 있는 경우 테이블의 삭제 방지를 위해서도 사용된다.
ㄷ.데이터무결성
• 1) 개체 무결성(Entity Integrity)
릴레이션에 저장되는 튜플(tuple)의 유일성을 보장하기 위한 제약조건이다. ==pk 고유키
• 2) 참조 무결성(Relational Integrity)
외래 키는 반드시 참조 키의 값과 일치하거나 null을 가져야 한다.
update emp
set deptno=90 --dept테이블에서는 90번 부서가 존재하지 않기 때문에
where empno=7369;
delete from dept
where deptno=30
오류 보고 -
ORA-02292: integrity constraint (SCOTT.FK_DEPTNO) violated - child record found
• 3) 도메인 무결성(domain integrity)
릴레이션 (테이블)간의 데이터의 일관성을 보장하기 위한 제약조건이다
kor number(3) not null default 0
도메인에 벗어나면 체크
제약 조건의 종류 5가지.
ㄱ. PRIMARY KEY 제약조건( 고유키 PK)
ㄴ. FOREIGN KEY 제약조건( 외래키, 참조키 FK )
ㄷ. NOT NULL 제약조건 (NN)
ㄹ. UNIQUE 제약조건 ( 유일성 UK )
ㅁ. CHECK 제약조건 ( CK )
not null은 칼럼 레밸 방식에만 ( 바로 옆에 쓰는거 )
복합키는 테이블 레벨 방식에만
CREATE TABLE tbl_constraint
(
empno number(4)
, ename varchar2(20)
, deptno number(2)
, kor number(3)
, email varchar2(50)
, city varchar2(20)
);
-- Table TBL_CONSTRAINT이(가) 생성되었습니다.
INSERT INTO tbl_constraint ( empno, ename, deptno, kor, email, city ) VALUES ( null, null, null, null, null, null );
-- 필수 입력 컬럼 지정 : NOT NULL 제약 조건
INSERT INTO tbl_constraint ( empno, ename, deptno, kor, email, city ) VALUES ( 1111, 'ADMIN', 10, null, null, null );
INSERT INTO tbl_constraint ( empno, ename, deptno, kor, email, city ) VALUES ( 1111, 'HONG', 20, null, null, null );
1 행 이(가) 삽입되었습니다.
SELECT * FROM tbl_constraint;
-- 컬럼 레벨 방식으로 제약조건 설정
CREATE TABLE tbl_column_level
(
empno number(4) NOT NULL CONSTRAINT PK_TBLCOLUMNLEVEL_EMPNO PRIMARY KEY
, ename varchar2(20) NOT NULL
-- dept 테이블의 PK(deptno) 컬럼을 참조하는 외래키.참조키 FK
, deptno number(2) NOT NULL CONSTRAINT FK_TBLCOLUMNLEVEL_DEPTNO REFERENCES DEPT( deptno )
, kor number(3) CONSTRAINT CK_TBLCOLUMNLEVEL_KOR CHECK( KOR BETWEEN 0 AND 100 ) -- -999~999 0~100 CK
, email varchar2(50) CONSTRAINT UK_TBLCOLUMNLEVEL_EMAIL UNIQUE -- 유일성 UK UNIQUE CONSTRAINT
, city varchar2(20) CONSTRAINT CK_TBLCOLUMNLEVEL_CITY CHECK( CITY IN ('서울','부산','대구','대전' ) )-- 서울 부산 대구 대전
);
-- 테이블 레벨 방식으로 제약조건 설정
-- NOT NULL X
DROP TABLE tbl_table_level PURGE;
CREATE TABLE tbl_table_level
(
empno number(4) NOT NULL
, ename varchar2(20) NOT NULL
, deptno number(2) NOT NULL
, kor number(3)
, email varchar2(50)
, city varchar2(20)
-- PK 제약 조건 설정
, CONSTRAINT PK_TBLTABLELEVEL_EMPNO PRIMARY KEY( empno ) -- 복합키
, CONSTRAINT FK_TBLTABLELEVEL_DEPTNO FOREIGN KEY(deptno) REFERENCES DEPT( deptno )
, CONSTRAINT UK_TBLTABLELEVEL_EMAIL UNIQUE( email )
, CONSTRAINT CK_TBLTABLELEVEL_KOR CHECK( KOR BETWEEN 0 AND 100 )
, CONSTRAINT CK_TBLTABLELEVEL_CITY CHECK( CITY IN ('서울','부산','대구','대전' ) )
);
-- ORA-00907: missing right parenthesis 오른쪽 괄호 빠졌다.
-- ORA-02264: name already used by an existing constraint
-- 3:10 수업 시작~~
-- ORA-01438: value larger than specified precision allowed for this column
INSERT INTO tbl_table_level ( empno, ename, deptno, kor, email, city )
VALUES ( '1111','ADMIN', 20, 90, 'admin@naver.com', '서울');
-- 개체 무결성
-- ORA-00001: unique constraint (SCOTT.PK_TBLTABLELEVEL_EMPNO) violated
-- PK = NN + UK
-- 참조 무결성
-- ORA-02291: integrity constraint (SCOTT.FK_TBLTABLELEVEL_DEPTNO) violated - parent key not found
-- 도메인 무결성 0<= <=100
-- ORA-02290: check constraint (SCOTT.CK_TBLTABLELEVEL_KOR) violated
-- 도메인 무결성
-- ORA-02290: check constraint (SCOTT.CK_TBLTABLELEVEL_CITY) violated
INSERT INTO tbl_table_level ( empno, ename, deptno, kor, email, city )
VALUES ( '2222','HONG', 30, 89, 'hong@naver.com', '대구');
-- DML 데이터 조작 X -> 제약 조건
-- ORA-01400: cannot insert NULL into ("SCOTT"."TBL_TABLE_LEVEL"."ENAME")
INSERT INTO tbl_table_level ( empno, ename, deptno, kor, email, city )
VALUES ( '3333', null , 30, null, null, null);
INSERT INTO tbl_table_level ( empno, ename, deptno, kor, email, city )
VALUES ( '3333', 'KENIK' , 30, null, null, null);
제약조건 변경
ALTER TABLE TBL_TABLE_LEVEL
DROP PRIMARY KEY;
-- Table TBL_TABLE_LEVEL이(가) 변경되었습니다.
ALTER TABLE TBL_TABLE_LEVEL
DROP CONSTRAINT PK_TBLTABLELEVEL_EMPNO;
-- 2) PK 기존 테이블 추가 : PK_TBLTABLELEVEL_EMPNO
【형식】
ALTER TABLE 테이블명
ADD [CONSTRAINT 제약조건명] 제약조건타입 (컬럼명);
ALTER TABLE TBL_TABLE_LEVEL
ADD CONSTRAINT PK_TBLTABLELEVEL_EMPNO PRIMARY KEY (empno);
alter table
add primary key (empno) ;
KOR 컬럼에 NN 제약 조건 추가
ALTER TABLE 테이블명
ADD CONSTRAINT 제약조건명 CHECK( kor IS NOT NULL );
또는
ALTER TABLE 테이블명
MODIFY kor NOT NULL;
제약조건 활성화/ 비활성화 == 삭제/추가
ALTER TABLE 테이블명
ENABLE CONSTRAINT 제약조건명
ALTER TABLE 테이블명
DISABLE CONSTRAINT 제약조건명 [ CASCADE ];• ON DELETE CASCADE 옵션을 이용하면 부모 테이블의 행이 삭제될 때 이를 참조한 자식 테이블의 행을 동시에 삭제할 수 있다.
• ON DELETE SET NULL은 자식 테이블이 참조하는 부모 테이블의 값이 삭제되면 자식 테이블의 값을 NULL 값으로 변경시킨다
ALTER TABLE tbl_emp
ADD CONSTRAINT FK_TBLEMP_DEPTNO FOREIGN KEY( deptno ) REFERENCES tbl_dept( deptno ) ON DELETE CASCADE;
8-2) FK 제약조건 다시 추가..
ALTER TABLE tbl_emp
ADD CONSTRAINT FK_TBLEMP_DEPTNO FOREIGN KEY( deptno ) REFERENCES tbl_dept( deptno ) ON DELETE SET NULL;NN 제외한 제약조건 복사되지 않는다
[ 조인(JOIN) 종류 ]
1. EQUI JOIN
2. NON-EQUI JOIN
3. INNER JOIN
4. OUTER JOIN
5. SELF JOIN
셀프조인
• 한 개의 테이블을 두 개의 테이블처럼 사용하기 위해 테이블 별명을 사용하여 한 테이블을 자체적으로 JOIN하여 사용한다.
• SELF JOIN은 테이블이 자신의 특정 컬럼을 참조하는 또 다른 하나의 컬럼을 가지고 있는 경우에 사용한다.
【형식】
SELECT alias1.컬럼명, alias2.컬럼명
FROM 같은테이블 alais1, 같은테이블 alais2
WHERE alias1.컬럼1명=alais2.컬럼2명;
【형식】
SELECT alias1.컬럼명, alias2.컬럼명
FROM 같은테이블 alais1 JOIN 같은테이블 alais2
ON alias1.컬럼1명=alais2.컬럼2명;
문제)사원번호/사원명/부서명 조회 + 직속상사(매니저) 사원명
select a.empno,a.ename, a.deptno , a.mgr, b.ename
from emp a, emp b
where a.mgr=b.empno;
select a.empno,a.ename, a.deptno , a.mgr, b.ename
from emp a join emp b on a.mgr=b.empno;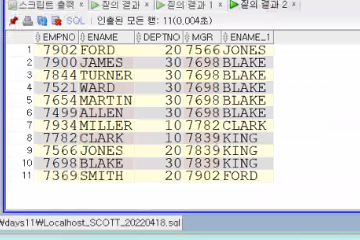
문제)사원번호/사원명/부서명 조회 + 직속상사(매니저) 사원명 +부서명
SELECT a.empno, a.ename, a.deptno, a.mgr , b.ename , dname
FROM emp a, emp b , dept d
WHERE a.mgr = b.empno AND a.deptno = d.deptno;
-- self join + equi join
SELECT a.empno, a.ename, a.deptno, a.mgr , b.ename , dname
FROM emp a JOIN emp b ON a.mgr = b.empno
JOIN dept d ON a.deptno = d.deptno;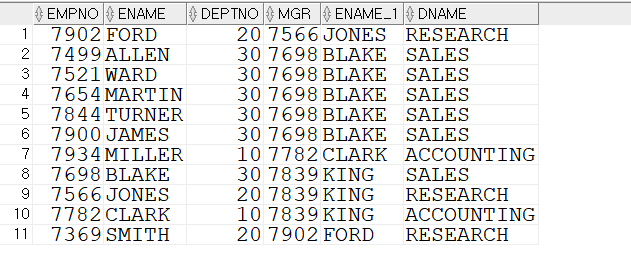
수업
-- SCOTT 계정 접속 --
-- 9:40 수업 시작~
1. truncate / delete / drop 대해서 설명하세요
DROP 테이블 객체 삭제
TRUNCATE 테이블 데이터(행) 삭제 + 자동 커밋 + 모든 행 삭제
DELETE 테이블 데이터(행) 삭제 + C/R + WHERE 조건절.
2. insert 문 수행 중 다음과 같은 오류가 발생했다면 이유에 대해 설명하세요
ㄱ. 00947. 00000 - "not enough values"
INSERT INTO 테이블명 ( 컬럼명 갯수) VALUES ( 컬럼값 ..)
ㄴ. ORA-00001: unique constraint (SCOTT.SYS_C007770) violated
deptno PK
INSERT INTO dept VALUES ( 10 ..);
ㄷ. ORA-02291: integrity constraint (SCOTT.FK_DEPTNO) violated - parent key not found
무결성 제약조건 위배
dept 테이블 10/20/30/40
INSERT INTO emp VALUES ( 50(deptno) )X
3. 서브쿼리를 사용해서 테이블 생성
ㄱ. deptno, dname, empno, ename, sal+nvl(comm,0) pay, grade 컬럼을 가진 새로운 테이블 생성
ㄴ. 테이블명 : tbl_empdeptgrade
emp
dept
salgrade
CREATE TABLE tbl_empdeptgrade
AS
(
SELECT deptno, dname, empno, ename, sal+nvl(comm,0) pay, grade
FROM dept d JOIN emp e ON d.deptno = e.deptno
JOIN salgrade s ON e.sal BETWEEN s.losal AND s.hisal
);
create table a
as(
select deptno, dname, empno, ename, sal+nvl(comm,0) pay, grade
from dept d join emp e on d.deptno=e.deptno
join salgrade s on e.sal between s.losal and s.hisal
)
select *
from dept;
select *
from emp;
select *
from salgrade;
4-1. insa 테이블에서 num, name 가져와서 tbl_score 테이블 생성
CREATE TABLE tbl_score
AS
( SELECT num, name FROM insa )
4-2. kor, eng, mat, tot , avg , grade, rank 컬럼 추가
ALTER TABLE tbl_score
ADD (
kor NUMBER(3)
,
);
4-3. 각 학생들의 kor,eng,mat 점수 0~100 랜덤하게 채워넣기.
UPDATE tbl_Score
SET kor = FLOOR( dbms_random.value(0, 101) )
, eng =
, mat =
;
4-4. 총점, 평균, 등급, 등수 수정
조건)
등급은 모든 과목이 40점이상이고, 평균 60 이상이면 "합격"
평균 60 이상이라도 한 과목이라 40점 미만이라면 "과락"
그외는 "불합격" 이라고 저장.
update tbl_score
set avg= (mat+kor+eng)/3,
grade =case
when mat>=40 and kor>=and eng>=40 and avg>=60 then '합격'
when (mat<=40 or kor<=40 or eng<=40) and avg>=60 then '괴락'
else '불합격'
end;
UPDATE tbl_score
SET
, avg = (kor+eng+mat)/3
, grade = CASE
WHEN kor>=40 AND eng>=40 AND mat >= 40 AND avg >=60 THEN '합격'
WHEN ( kor<40 OR eng<40 OR mat < 40 ) AND avg >=60 THEN '과락'
ELSE '불합격'
END;
5. emp 테이블의 구조를 확인하고, 제약조건을 확인하고, 임의의 사원 정보를 추가하는 INSERT 문을 작성하세요.
ㄱ. 구조확인 쿼리
DESC emp;
ㄴ. 제약조건 확인 쿼리
FROM user_constraints;
FROM user_tables;
select *
FROM tabs;
ㄷ. INSERT 쿼리
6-1. emp 테이블의 구조만 복사해서 새로운 tbl_emp10, tbl_emp20, tbl_emp30, tbl_emp40 테이블을 생성하세요.
CREATE TABLE tbl_emp10
AS SELECT * FROM emp WHERE 1=0;
6-2. emp 테이블의 각 부서에 해당하는 사원정보를 위에서 생성한 테이블에 INSERT 하는 쿼리를 작성하세요.
-- 조건이 있는 다중 INSERT문
INSERT ALL
--INSERT FIRST
--WHEN deptno = 10 THEN
INTO tbl_emp10 VALUES ( 컬럼명...)
WHEN deptno = 20 THEN
INTO tbl_emp20 VALUES ( 컬럼명...)
WHEN deptno = 30 THEN
INTO tbl_emp30 VALUES ( 컬럼명...)
WHEN deptno = 40 THEN
INTO tbl_emp40 VALUES ( 컬럼명...)
SELECT * FROM emp;
7. 조건이 있는 다중 INSERT 문에서 INSERT ALL 과 INSERT FIRST 문에 대한 차이점을 설명하세요.
-------------------------------------------------------------------------------------------
문제) 여자 학생들만 영어 점수 5점 증가
UPDATE tbl_score
SET eng = eng+5
WHERE num = (
SELECT ts.num
FROM tbl_score ts,(
SELECT num, DECODE (MOD( SUBSTR(ssn, -7,1),2),0,'여자') gender
FROM insa)i
WHERE ts.num = i.num AND gender IS NOT NULL
) ;
-- ANY 연산자
UPDATE tbl_score
SET eng = eng + 5
-- 1003 , 1005
WHERE num = ANY (
SELECT num
FROM insa
WHERE MOD(SUBSTR(ssn, -7, 1), 2) = 0 AND num <= 1005
);
update tbl_score
set eng=eng+5
where num= any(
select num
from insa
where mod(substr(ssn,8,1),2)=0
)
-- X 1003 , 1005
WHERE num IN (
SELECT num
FROM insa
WHERE MOD(SUBSTR(ssn, -7, 1), 2) = 0 AND num <= 1005
);
sELECT *
FROM tbl_Score;
--------------------------------------------------------------------------------------------
-- 만년달력 2020 04
-- LEVEL 의사컬럼
SELECT dates
, TO_CHAR( dates , 'D') D -- 1(일) 2(월) 3(화) 7(토)
, TO_CHAR( dates , 'DY') DY
, TO_CHAR( dates , 'DAY') DAY
-- 일요일 그 전주로 처리..
, TO_CHAR( dates , 'IW') IW
, CASE
WHEN TO_CHAR( dates , 'D') = 1 THEN TO_CHAR( dates , 'IW') + 1
ELSE TO_NUMBER( TO_CHAR( dates , 'IW') )
END "IW2"
, TO_CHAR( dates , 'WW') WW
, TO_CHAR( dates , 'W') W -- 해당 달의 1~7일 한주
, CASE
WHEN TO_CHAR( dates, 'D' ) < TO_CHAR( TO_DATE( :yyyymm,'YYYYMM' ), 'D' )
THEN TO_CHAR( dates, 'W' ) + 1
ELSE TO_NUMBER( TO_CHAR( dates, 'W' ) )
END NW
FROM (
SELECT TO_DATE(:yyyymm , 'YYYYMM') + LEVEL - 1 dates
FROM dual
CONNECT BY LEVEL <= EXTRACT ( DAY FROM LAST_DAY(TO_DATE(:yyyymm , 'YYYYMM') ) )
) t ;
-------------------------------------------------------- KENIK -------------------------------
SELECT
NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 1, TO_CHAR( dates, 'DD')) ), ' ') 일
, NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 2, TO_CHAR( dates, 'DD')) ), ' ') 월
, NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 3, TO_CHAR( dates, 'DD')) ), ' ') 화
, NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 4, TO_CHAR( dates, 'DD')) ), ' ') 수
, NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 5, TO_CHAR( dates, 'DD')) ), ' ') 목
, NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 6, TO_CHAR( dates, 'DD')) ), ' ') 금
, NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 7, TO_CHAR( dates, 'DD')) ), ' ') 토
FROM (
SELECT TO_DATE(:yyyymm , 'YYYYMM') + LEVEL - 1 dates
FROM dual
CONNECT BY LEVEL <= EXTRACT ( DAY FROM LAST_DAY(TO_DATE(:yyyymm , 'YYYYMM') ) )
) t
GROUP BY CASE
-- IW 가 50주 넘으면서 "일요일"
WHEN TO_CHAR(dates, 'D') = '1' AND TO_CHAR( dates, 'IW') > '50' THEN 1
WHEN TO_CHAR(dates, 'D') != '1' AND TO_CHAR( dates, 'IW') > '50' THEN 0
WHEN TO_CHAR( dates , 'D') = 1 THEN TO_CHAR( dates , 'IW') + 1
ELSE TO_NUMBER( TO_CHAR( dates , 'IW') )
END
ORDER BY CASE
WHEN TO_CHAR(dates, 'D') = '1' AND TO_CHAR( dates, 'IW') > '50' THEN 1
WHEN TO_CHAR(dates, 'D') != '1' AND TO_CHAR( dates, 'IW') > '50' THEN 0
WHEN TO_CHAR( dates , 'D') = 1 THEN TO_CHAR( dates , 'IW') + 1
ELSE TO_NUMBER( TO_CHAR( dates , 'IW') )
END;
---
SELECT deptno, max(sal), min(sal)
FROM emp
GROUP BY deptno;
-------------------------------------------------------- KENIK -------------------------------
SELECT
NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 1, TO_CHAR( dates, 'DD')) ), ' ') 일
, NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 2, TO_CHAR( dates, 'DD')) ), ' ') 월
, NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 3, TO_CHAR( dates, 'DD')) ), ' ') 화
, NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 4, TO_CHAR( dates, 'DD')) ), ' ') 수
, NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 5, TO_CHAR( dates, 'DD')) ), ' ') 목
, NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 6, TO_CHAR( dates, 'DD')) ), ' ') 금
, NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 7, TO_CHAR( dates, 'DD')) ), ' ') 토
FROM (
SELECT TO_DATE(:yyyymm , 'YYYYMM') + LEVEL - 1 dates
FROM dual
CONNECT BY LEVEL <= EXTRACT ( DAY FROM LAST_DAY(TO_DATE(:yyyymm , 'YYYYMM') ) )
) t
GROUP BY CASE
-- IW 가 50주 넘으면서 "일요일"
WHEN TO_CHAR(dates, 'MM') = 1 AND TO_CHAR(dates, 'D') = '1' AND TO_CHAR( dates, 'IW') > '50' THEN 1
WHEN TO_CHAR(dates, 'MM') = 1 AND TO_CHAR(dates, 'D') != '1' AND TO_CHAR( dates, 'IW') > '50' THEN 0
WHEN TO_CHAR( dates , 'D') = 1 THEN TO_CHAR( dates , 'IW') + 1
ELSE TO_NUMBER( TO_CHAR( dates , 'IW') )
END
ORDER BY
CASE
WHEN TO_CHAR(dates, 'MM') = 1 AND TO_CHAR(dates, 'D') = '1' AND TO_CHAR( dates, 'IW') > '50' THEN 1
WHEN TO_CHAR(dates, 'MM') = 1 AND TO_CHAR(dates, 'D') != '1' AND TO_CHAR( dates, 'IW') > '50' THEN 0
WHEN TO_CHAR( dates , 'D') = 1 THEN TO_CHAR( dates , 'IW') + 1
ELSE TO_NUMBER( TO_CHAR( dates , 'IW') )
END ;
-- 그런데 50주 이상으로 처리하면 22년 12월 달력이 이상해지지 않을까요?
-- 학생 --
-- 11:10 수업시작 ---
SELECT
NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 1, TO_CHAR( dates, 'DD')) ), ' ') 일
, NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 2, TO_CHAR( dates, 'DD')) ), ' ') 월
, NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 3, TO_CHAR( dates, 'DD')) ), ' ') 화
, NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 4, TO_CHAR( dates, 'DD')) ), ' ') 수
, NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 5, TO_CHAR( dates, 'DD')) ), ' ') 목
, NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 6, TO_CHAR( dates, 'DD')) ), ' ') 금
, NVL( MIN( DECODE( TO_CHAR( dates, 'D'), 7, TO_CHAR( dates, 'DD')) ), ' ') 토
FROM (
SELECT TO_DATE(:yyyymm , 'YYYYMM') + LEVEL - 1 dates
FROM dual
CONNECT BY LEVEL <= EXTRACT ( DAY FROM LAST_DAY(TO_DATE(:yyyymm , 'YYYYMM') ) )
) t
GROUP BY CASE
-- 1/2/3/4/5/6/7 2022/04/1의 요일
WHEN TO_CHAR( dates, 'D' ) < TO_CHAR( TO_DATE( :yyyymm,'YYYYMM' ), 'D' )
THEN TO_CHAR( dates, 'W' ) + 1
ELSE TO_NUMBER( TO_CHAR( dates, 'W' ) )
END
ORDER BY CASE
WHEN TO_CHAR( dates, 'D' ) < TO_CHAR( TO_DATE( :yyyymm,'YYYYMM' ), 'D' ) THEN TO_CHAR( dates, 'W' ) + 1
ELSE TO_NUMBER( TO_CHAR( dates, 'W' ) )
END;
---------------------------------------------------------------------------------------------
LEVEL 의사컬럼
--------------------------------------------------------------------------------
【참조】테이블에서 행(row)의 LEVEL(레벨)를 가리키는 일련번호 순서
[LEVEL 함수]
ㄱ. CONNECT_BY_ISLEAF 더 이상 LEAF 데이터가 없으면 1, 있으면 0을 반환
ㄴ. CONNECT_BY_ISCYCLE root 데이터이면 1, 아니면 0을 반환
ㄷ. CONNECT_BY_ROOT 각 데이터의 root값과 LEVEL 값을 반환
[ 계층적 질의 (hierarchical query) ]
ㄱ. 계층적 질의문은 조인문이나 뷰에서는 사용할 수 없으며,
ㄴ. CONNECT BY 절에서는 서브쿼리 절을 포함할 수 없다.
ㄷ. 【형식】
SELECT [LEVEL] {*,컬럼명 [alias],...}
FROM 테이블명
WHERE 조건
START WITH 조건
CONNECT BY [PRIOR 컬럼1명 비교연산자 컬럼2명]
또는
[컬럼1명 비교연산자 PRIOR 컬럼2명]
ㄹ. PRIOR 위치 : TOP-DOWN 방식, BOTTOM-UP 방식
ㅁ. 테스트
SELECT empno,ename,mgr,deptno
FROM emp;
-- 계층적 질의
SELECT empno, ename, mgr , LEVEL
FROM emp
--START WITH empno = 7839 -- 최고 레벨 ( mgr 없는 사원 : KING )
START WITH mgr IS NULL
CONNECT BY PRIOR empno = mgr ; -- empno/mgr TOP-DOWN방식 PRIOR 자식키 = 부모키
SELECT LPAD( ' ', 3*LEVEL-3 ) || ename
, empno, mgr , LEVEL
, SYS_CONNECT_BY_PATH( ename, '/') path
, CONNECT_BY_ROOT ename ROOT_NODE
, connect_by_isleaf
FROM emp
START WITH mgr IS NULL
CONNECT BY PRIOR empno = mgr ;
-- 사용하는 곳 ? 답변형 게시판을 구현할 때 계층적 질의 사용하면 된다.
게시글 글번호 empno 부모게시글번호 mgr
X
왜? DBMS 오라클에서만 사용할 수 있어요..
예)
-- 테이블의 dname 컬럼 크기 20->30 수정
DESC tbl_level;
create table tbl_level(
deptno number(3) not null primary key,
dname varchar2(30) not null,
college number(3),
loc varchar2(10)
);
-- Table TBL_LEVEL이(가) 생성되었습니다.
insert into tbl_level ( deptno, dname, college, loc ) values ( 10,'공과대학', null , null);
insert into tbl_level ( deptno, dname, college, loc ) values ( 100,'정보미디어학부',10, null );
insert into tbl_level ( deptno, dname, college, loc ) values ( 101,'컴퓨터공학과',100,'1호관');
insert into tbl_level ( deptno, dname, college, loc ) values ( 102,'멀티미디어학과',100,'2호관');
insert into tbl_level ( deptno, dname, college, loc ) values ( 200,'메카트로닉스학부', 10,null);
insert into tbl_level ( deptno, dname, college, loc ) values ( 201,'전자공학과',200,'3호관');
insert into tbl_level ( deptno, dname, college, loc ) values ( 202,'기계공학과',200,'4호관');
SELECT *
FROM tbl_level;
ROLLBACK;
COMMIT;
--
SELECT LPAD( ' ', (LEVEL-1)*3 ) || dname 조직도
, deptno, college, level
FROM tbl_level
START WITH deptno = 10
CONNECT BY PRIOR deptno = college ; -- TOP-DOWN 방식
12:07 수업시작.~
-- 정보미디어학부 가지를 삭제
SELECT LPAD( ' ', (LEVEL-1)*3 ) || dname 조직도
, deptno, college, level
FROM tbl_level
WHERE dname != '정보미디어학부'
START WITH deptno = 10
CONNECT BY PRIOR deptno = college ; -- TOP-DOWN 방식
-- 정보미디어학부 + 하위(자식) 가지도 삭제 : CONNECT BY 절 사용.
SELECT LPAD( ' ', (LEVEL-1)*3 ) || dname 조직도
, deptno, college, level
FROM tbl_level
-- WHERE dname != '정보미디어학부'
START WITH deptno = 10
CONNECT BY PRIOR deptno = college AND dname != '정보미디어학부' ; -- TOP-DOWN 방식
-- MERGE( 병합, 통합 ) --
ㄱ. "구조가 같은" 두 개의 테이블을 비교하여
-> 하나의 테이블로 합치기 위한 데이터 조작이다
ㄴ. UNION, UNION ALL 차이점 ? A U B
ㄷ. 사용하는 곳 ? A <- B
하루에 수만건씩 발생하는 데이터를 하나의 테이블에 관리할 경우 대량의 데이터로 인해 질의문의 성능이 저하된다.
이런 경우, 지점별로 별도의 테이블에서 관리하다가 년말에 종합 분석을 위해 하나의 테이블로 합칠 때 merge 문을 사용하면 편리하다.
ㄹ. merge하고자 하는 소스 테이블의 행을 읽어 타킷
테이블에 매치되는 행이 존재하면 새로운 값으로 UPDATE를 수행하고,
만일 매치되는 행이 없을 경우 새로운 행을 타킷 테이블에서 INSERT를 수행한다.
A <- B
X 13(update) Y 5
Y 5 (insert) X 3
ㅁ.
【형식】
MERGE [hint] INTO [schema.] {table ¦ view} [t_alias]
USING {{[schema.] {table ¦ view}} ¦
subquery} [t_alias]
ON (condition) [merge_update_clause] [merge_insert_clause] [error_logging_clause];
【merge_update_clause 형식】
WHEN MATCHED THEN UPDATE SET {column = {expr ¦ DEFAULT},...}
[where_clause] [DELETE where_clause]
【merge_insert_clause 형식】
WHEN NOT MATCHED THEN INSERT [(column,...)]
VALUES ({expr,... ¦ DEFAULT}) [where_clause]
【where_clause 형식】
WHERE condition
【error_logging_clause 형식】
LOG ERROR [INTO [schema.] table] [(simple_expression)]
[REJECT LIMIT {integer ¦ UNLIMITED}]
ㅂ. 테스트
create table tbl_emp(
id number primary key, -- 사원ID(PK)
name varchar2(10) not null, -- 사원명
salary number, -- 기본급
bonus number default 100 -- 보너스 100(기본값)
);
-- Table TBL_EMP이(가) 생성되었습니다.
insert into tbl_emp(id,name,salary) values(1001,'jijoe',150);
insert into tbl_emp(id,name,salary) values(1002,'cho',130);
insert into tbl_emp(id,name,salary) values(1003,'kim',140);
COMMIT;
SELECT *
FROM tbl_emp;
create table tbl_bonus(
id number
, bonus number default 100
);
-- Table TBL_BONUS이(가) 생성되었습니다.
INSERT INTO tbl_bonus ( id ) ( SELECT id FROM tbl_emp);
COMMIT;
SELECT *
FROM tbl_bonus;
1001 100
1002 100
1003 100
1004 50
INSERT INTO tbl_bonus VALUES ( 1004, 50 );
tbl_emp
1001 jijoe 150 100
1002 cho 130 100
1003 kim 140 100
-- 병합 tbl_emp -> tbl_bonus
--INSERT INTO tbl_bonus
MERGE INTO tbl_bonus b
USING ( SELECT id, salary FROM tbl_emp ) e
ON ( b.id = e.id )
WHEN MATCHED THEN -- UPDATE
UPDATE SET b.bonus = b.bonus + e.salary*0.01
WHEN NOT MATCHED THEN -- INSERT
INSERT ( b.id, b.bonus ) VALUES ( e.id, e.salary*0.01 );
SELECT *
FROM tbl_bonus;
1001 100
1002 100
1003 100
1004 50
1001 101.5
1002 101.3
1003 101.4
1004 50
-- 병합 문제)
CREATE TABLE tbl_merge1
(
id number primary key
, name varchar2(20)
, pay number
, sudang number
);
CREATE TABLE tbl_merge2
(
id number primary key
, sudang number
);
INSERT INTO tbl_merge1 (id, name, pay, sudang) VALUES (1, 'a', 100, 10);
INSERT INTO tbl_merge1 (id, name, pay, sudang) VALUES (2, 'b', 150, 20);
INSERT INTO tbl_merge1 (id, name, pay, sudang) VALUES (3, 'c', 130, 0);
INSERT INTO tbl_merge2 (id, sudang) VALUES (2,5);
INSERT INTO tbl_merge2 (id, sudang) VALUES (3,10);
INSERT INTO tbl_merge2 (id, sudang) VALUES (4,20);
COMMIT;
--
SELECT *
FROM tbl_merge1;
1 a 100 10
2 b 150 20
3 c 130 0
SELECT *
FROM tbl_merge2;
2 5
3 10
4 20
--MERGE (병합)
2 25 UPDATE
3 10 UPDATE
4 20
1 10 INSERT
merge int tbl_merge2 t2
using (select id, sudang from tbl_merge1) t1
on(t1.id =t2.id)
when matched then
update sudang=sudang+5
when not matched then
insert (t2.id, t2.sudang) values (t1.id, t1.sudang)
MERGE INTO tbl_merge2 t2
USING ( SELECT id, sudang
FROM tbl_merge1 ) t1
ON ( t1.id = t2.id )
WHEN MATCHED THEN -- UPDATE
UPDATE SET t2.sudang = t2.sudang + t1.sudang
WHEN NOT MATCHED THEN -- INSERT
INSERT (t2.id, t2.sudang) VALUES ( t1.id, t1.sudang );
SELECT *
FROM tbl_merge2;
-- 오후 ~
-- 제약조건[constraint] --
1. 테이블에 제약 조건 확인 : user_constraints 뷰(view);
SELECT *
FROM user_constraints
WHERE table_name = 'EMP';
SCOTT PK_EMP P EMP ENABLED
SCOTT FK_DEPTNO R EMP SCOTT PK_DEPT NO ACTION ENABLED
2. 제약 조건 ?
ㄱ. 데이터 무결성(integrity constraint )을 위해서 테이블에 레코드(행)을 추가, 수정, 삭제할 때 적용되는 규칙
ㄴ. 테이블의 삭제 방지를 위해서도 제약조건을 사용한다.
DEPT( deptno PK ) -- EMP ( deptno FK )
DELETE FROM dept
WHERE deptno = 30;
-- ORA-02292: integrity constraint (SCOTT.FK_DEPTNO) violated - child record found
SELECT *
FROM emp
WHERE deptno = 30;
ㄷ. 데이터 무결성? 데이터가 허가되지 않는 값으로 추가,수정,삭제 제한하는 특성
• 1) 개체 무결성(Entity Integrity)
SELECT * FROM Dept;
deptno = 10;
INSERT INTO dept VALUES ( 10, 'QC', 'SEOUL');
-- ORA-00001: unique constraint (SCOTT.PK_DEPT) violated
- 릴레이션(table)에 저장되는 튜플(tuple == 행 == row == record )의 유일성을 보장하기 위한 제약조건이다 == PK 고유키
• 2) 참조 무결성(Relational Integrity)
UPDATE emp
SET deptno = 90 -- dept테이블에서는 90 번 부서가 존재하지 않기때문에 참조할 수 없다.
WHERE empno = 7369;
ORA-02291: integrity constraint (SCOTT.FK_DEPTNO) violated - parent key not found
- 릴레이션(테이블) 간의 데이터의 [일관성]을 보장하기 위한 제약조건이다
- dept테이블 :10,20,30,40
- emp 테이블 : 90번 사원 존재하면 안되잖아요..
• 3) 도메인 무결성(domain integrity)
컬럼(속성)의 값의 데이터 타입, 길이, 기본 키, [유일성], null 허용, 허용 제약 조건
예) 국어 점수
kor NUMBER(3) NOT NULL DEFAULT 0 입력을 하지 않으면 기본값 0 으로 입력
필수 입력 사항 NOT NULL
-999~999 정수를 저장할 수 있다. 0<= 정수 <=100 ( 범위 제한 )
--
예) 주민등록번호
개체,참조, [도메인 무결성..] 위배 - > 제약조건 설정
rrn char(14) INSERT INTO 테이블명 ( rrn ) VAluES ( '123' );
rrn char(14) INSERT INTO 테이블명 ( rrn ) VAluES ( '123' );
3. 제약조건을 사용하는 이유 ? DML 할 때 잘못 조작되는 것을 방지하기 위해서...
DML = insert, update, delete
4. 제약 조건을 선언(설정)하는 방법
ㄱ. CREATE TABLE 테이블 생성
ㄴ. ALTER TABLE 테이블 수정..
CREATE TABLE XXX
(
id 자료형 NOT NULL PRIMARY KEY --
cnt DEFAULT 0
)
5. 제약 조건의 종류 5가지.
ㄱ. PRIMARY KEY 제약조건( 고유키 PK)
ㄴ. FOREIGN KEY 제약조건( 외래키, 참조키 FK )
ㄷ. NOT NULL 제약조건 (NN)
ㄹ. UNIQUE 제약조건 ( 유일성 UK )
ㅁ. CHECK 제약조건 ( CK )
6. 제약조건을 생성하는 2가지 방법
ㄱ. 컬럼 레벨( column level ) == IN-LINE constaint 방법
ㄴ. 테이블 레벨( table level ) == OUT-OF-LINE constaint 방법
-- 제약조건 X
DROP TABLE tbl_constraint;
ROLLBACK;
CREATE TABLE tbl_constraint
(
empno number(4)
, ename varchar2(20)
, deptno number(2)
, kor number(3)
, email varchar2(50)
, city varchar2(20)
);
-- Table TBL_CONSTRAINT이(가) 생성되었습니다.
INSERT INTO tbl_constraint ( empno, ename, deptno, kor, email, city ) VALUES ( null, null, null, null, null, null );
-- 필수 입력 컬럼 지정 : NOT NULL 제약 조건
INSERT INTO tbl_constraint ( empno, ename, deptno, kor, email, city ) VALUES ( 1111, 'ADMIN', 10, null, null, null );
INSERT INTO tbl_constraint ( empno, ename, deptno, kor, email, city ) VALUES ( 1111, 'HONG', 20, null, null, null );
1 행 이(가) 삽입되었습니다.
SELECT * FROM tbl_constraint;
-- 컬럼 레벨 방식으로 제약조건 설정
CREATE TABLE tbl_column_level
(
empno number(4) NOT NULL CONSTRAINT PK_TBLCOLUMNLEVEL_EMPNO PRIMARY KEY
, ename varchar2(20) NOT NULL
-- dept 테이블의 PK(deptno) 컬럼을 참조하는 외래키.참조키 FK
, deptno number(2) NOT NULL CONSTRAINT FK_TBLCOLUMNLEVEL_DEPTNO REFERENCES DEPT( deptno )
, kor number(3) CONSTRAINT CK_TBLCOLUMNLEVEL_KOR CHECK( KOR BETWEEN 0 AND 100 ) -- -999~999 0~100 CK
, email varchar2(50) CONSTRAINT UK_TBLCOLUMNLEVEL_EMAIL UNIQUE -- 유일성 UK UNIQUE CONSTRAINT
, city varchar2(20) CONSTRAINT CK_TBLCOLUMNLEVEL_CITY CHECK( CITY IN ('서울','부산','대구','대전' ) )-- 서울 부산 대구 대전
);
-- 테이블 레벨 방식으로 제약조건 설정
-- NOT NULL X
DROP TABLE tbl_table_level PURGE;
CREATE TABLE tbl_table_level
(
empno number(4) NOT NULL
, ename varchar2(20) NOT NULL
, deptno number(2) NOT NULL
, kor number(3)
, email varchar2(50)
, city varchar2(20)
-- PK 제약 조건 설정
, CONSTRAINT PK_TBLTABLELEVEL_EMPNO PRIMARY KEY( empno ) -- 복합키
, CONSTRAINT FK_TBLTABLELEVEL_DEPTNO FOREIGN KEY(deptno) REFERENCES DEPT( deptno )
, CONSTRAINT UK_TBLTABLELEVEL_EMAIL UNIQUE( email )
, CONSTRAINT CK_TBLTABLELEVEL_KOR CHECK( KOR BETWEEN 0 AND 100 )
, CONSTRAINT CK_TBLTABLELEVEL_CITY CHECK( CITY IN ('서울','부산','대구','대전' ) )
);
-- ORA-00907: missing right parenthesis 오른쪽 괄호 빠졌다.
-- ORA-02264: name already used by an existing constraint
-- 3:10 수업 시작~~
-- ORA-01438: value larger than specified precision allowed for this column
INSERT INTO tbl_table_level ( empno, ename, deptno, kor, email, city )
VALUES ( '1111','ADMIN', 20, 90, 'admin@naver.com', '서울');
-- 개체 무결성
-- ORA-00001: unique constraint (SCOTT.PK_TBLTABLELEVEL_EMPNO) violated
-- PK = NN + UK
-- 참조 무결성
-- ORA-02291: integrity constraint (SCOTT.FK_TBLTABLELEVEL_DEPTNO) violated - parent key not found
-- 도메인 무결성 0<= <=100
-- ORA-02290: check constraint (SCOTT.CK_TBLTABLELEVEL_KOR) violated
-- 도메인 무결성
-- ORA-02290: check constraint (SCOTT.CK_TBLTABLELEVEL_CITY) violated
INSERT INTO tbl_table_level ( empno, ename, deptno, kor, email, city )
VALUES ( '2222','HONG', 30, 89, 'hong@naver.com', '대구');
-- DML 데이터 조작 X -> 제약 조건
-- ORA-01400: cannot insert NULL into ("SCOTT"."TBL_TABLE_LEVEL"."ENAME")
INSERT INTO tbl_table_level ( empno, ename, deptno, kor, email, city )
VALUES ( '3333', null , 30, null, null, null);
INSERT INTO tbl_table_level ( empno, ename, deptno, kor, email, city )
VALUES ( '3333', 'KENIK' , 30, null, null, null);
SELECT *
FROM tbl_table_level;
-- tbl_table_level 제약 조건 확인
SELECT *
FROM user_constraints
WHERE table_name = UPPER('tbl_table_level');
SCOTT SYS_C008399 C TBL_TABLE_LEVEL
SCOTT SYS_C008400 C TBL_TABLE_LEVEL
SCOTT SYS_C008401 C TBL_TABLE_LEVEL
SCOTT CK_TBLTABLELEVEL_KOR C TBL_TABLE_LEVEL
SCOTT CK_TBLTABLELEVEL_CITY C TBL_TABLE_LEVEL
SCOTT PK_TBLTABLELEVEL_EMPNO P TBL_TABLE_LEVEL
SCOTT UK_TBLTABLELEVEL_EMAIL U TBL_TABLE_LEVEL
SCOTT FK_TBLTABLELEVEL_DEPTNO R TBL_TABLE_LEVEL
-- TBL_TABLE_LEVEL 테이블에서 PK 제약 조건을 제거
ALTER TABLE 테이블명
DROP [CONSTRAINT constraint명 | PRIMARY KEY | UNIQUE(컬럼명)]
***** [CASCADE] *****;
-- 1) PK 삭제
alter table
drop primary key;
ALTER TABLE TBL_TABLE_LEVEL
DROP PRIMARY KEY;
-- Table TBL_TABLE_LEVEL이(가) 변경되었습니다.
ALTER TABLE TBL_TABLE_LEVEL
DROP CONSTRAINT PK_TBLTABLELEVEL_EMPNO;
-- 2) PK 기존 테이블 추가 : PK_TBLTABLELEVEL_EMPNO
【형식】
ALTER TABLE 테이블명
ADD [CONSTRAINT 제약조건명] 제약조건타입 (컬럼명);
ALTER TABLE TBL_TABLE_LEVEL
ADD CONSTRAINT PK_TBLTABLELEVEL_EMPNO PRIMARY KEY (empno);
alter table
add primary key (empno) ;
-- 문제) 1. 제약 조건을 확인하고
-- 2. 모든 CK 삭제(제거)
-- TBL_TABLE_LEVEL 테이블에서
SCOTT CK_TBLTABLELEVEL_KOR C TBL_TABLE_LEVEL
SCOTT CK_TBLTABLELEVEL_CITY C TBL_TABLE_LEVEL
ALTER TABLE TBL_TABLE_LEVEL
DROP CONSTRAINT CK_TBLTABLELEVEL_KOR;
ALTER TABLE TBL_TABLE_LEVEL
DROP CONSTRAINT CK_TBLTABLELEVEL_CITY;
-- 문제) kor 컬럼은 NN 제약 조건 설정이 안되어 있어요..
-- KOR 컬럼에 NN 제약 조건 추가하세요...
ALTER TABLE 테이블명
ADD CONSTRAINT 제약조건명 CHECK( kor IS NOT NULL );
또는
ALTER TABLE 테이블명
MODIFY kor NOT NULL;
-- 제약조건 활성화/ 비활성화 == 삭제/추가
ALTER TABLE 테이블명
ENABLE CONSTRAINT 제약조건명
ALTER TABLE 테이블명
DISABLE CONSTRAINT 제약조건명 [ CASCADE ];
-- 4:00 수업 시작~
-- **** FK 설정시 두 가지 옵션 설명
• ON DELETE CASCADE 옵션을 이용하면 부모 테이블의 행이 삭제될 때 이를 참조한 자식 테이블의 행을 동시에 삭제할 수 있다.
• ON DELETE SET NULL은 자식 테이블이 참조하는 부모 테이블의 값이 삭제되면 자식 테이블의 값을 NULL 값으로 변경시킨다.
1)
emp -> tbl_emp 테이블 생성
dept -> tbl_dept 테이블 생성
DROP TABLE tbl_emp PURGE;
CREATE TABLE tbl_emp AS ( SELECT * FROM emp );
CREATE TABLE tbl_dept AS ( SELECT * FROM dept );
NN 제외한 제약조건 복사되지 않는다
2) tbl_emp 제약 조건 , tbl_dept 제약 조건 확인
SELECT *
FROM user_constraints
WHERE table_name IN ( 'TBL_EMP', 'TBL_DEPT');
3) tbl_emp , tbl_dept 제약 조건 : PK 추가
PK_테이블명_컬럼명 empno / deptno
ALTER TABLE tbl_emp
ADD CONSTRAINT PK_TBLEMP_EMPNO PRIMARY KEY( empno );
ALTER TABLE tbl_dept
ADD CONSTRAINT PK_TBLDEPT_DEPTNO PRIMARY KEY( deptno );
4) tbl_dept( deptno PK )--> tbl_emp( deptno )참조키 FK 설정
ALTER TABLE tbl_emp
ADD CONSTRAINT FK_TBLEMP_DEPTNO FOREIGN KEY( deptno ) REFERENCES tbl_dept( deptno );
SCOTT PK_TBLDEPT_DEPTNO P
SCOTT PK_TBLEMP_EMPNO P
SCOTT FK_TBLEMP_DEPTNO R
5) 조회
SELECT *FROM tbl_emp;
SELECT * FROM tbl_dept;
6) tbl_dept 테이블에서 30번 부서를 삭제
DELETE FROM tbl_dept
WHErE deptno = 30;
-- ORA-02292: integrity constraint (SCOTT.FK_TBLEMP_DEPTNO) violated - child record found
-- tbl_emp 테이블에 30번 부서원도 같이 삭제 시키고 싶다. ON DELETE CASCADE 옵션
7) FK_TBLEMP_DEPTNO 제약조건 삭제
ALTER TABLE tbl_emp
DROP CONSTRAINT FK_TBLEMP_DEPTNO;
8) FK 제약조건 다시 추가..
ALTER TABLE tbl_emp
ADD CONSTRAINT FK_TBLEMP_DEPTNO FOREIGN KEY( deptno ) REFERENCES tbl_dept( deptno ) ON DELETE CASCADE;
8-2) FK 제약조건 다시 추가..
ALTER TABLE tbl_emp
ADD CONSTRAINT FK_TBLEMP_DEPTNO FOREIGN KEY( deptno ) REFERENCES tbl_dept( deptno ) ON DELETE SET NULL;
9)
DELETE FROM tbl_dept
WHERE deptno = 30;
SELECT * FROM tbl_dept;
SELECT * FROM tbl_emp;
ROLLBACK;
-- [ JOIN ( 조인 ) ] --
-- 같거나 서로 다른 두 개 이상의 테이블에서 컬럼을 검색(조회)하기 위해서 사용한다.
부서명/사원명/입사일자
dept : 부서명
emp : 사원명/입사일자
-- RDBMS == 관계형 데이터 모델을 사용하는 DBMS
-- 테이블 <=> 테이블
-- PK FK
-- [ 조인(JOIN) 종류 ]
1. EQUI JOIN
2. NON-EQUI JOIN
3. INNER JOIN
4. OUTER JOIN
5. SELF JOIN
• 한 개의 테이블을 두 개의 테이블처럼 사용하기 위해 테이블 별명을 사용하여 한 테이블을 자체적으로 JOIN하여 사용한다.
• SELF JOIN은 테이블이 자신의 특정 컬럼을 참조하는 또 다른 하나의 컬럼을 가지고 있는 경우에 사용한다.
【형식】
SELECT alias1.컬럼명, alias2.컬럼명
FROM 같은테이블 alais1, 같은테이블 alais2
WHERE alias1.컬럼1명=alais2.컬럼2명;
【형식】
SELECT alias1.컬럼명, alias2.컬럼명
FROM 같은테이블 alais1 JOIN 같은테이블 alais2
ON alias1.컬럼1명=alais2.컬럼2명;
SELECT *
FROM emp;
문제) 사원번호/사원명/부서명 조회 + 직속상사(매니저) 사원명 + 부서명
dept :dname
select a.empno , a.ename, a.deptno, a.mgr, b.ename, dname
from emp a, emp b, dept d
where a.mgr=b.empno and a.deptno=d.deptno;
SELECT a.empno, a.ename, a.deptno, a.mgr , b.ename , dname
FROM emp a, emp b , dept d
WHERE a.mgr = b.empno AND a.deptno = d.deptno;
-- self join + equi join
SELECT a.empno, a.ename, a.deptno, a.mgr , b.ename , dname
FROM emp a JOIN emp b ON a.mgr = b.empno
JOIN dept d ON a.deptno = d.deptno;
from emp a join emp b on a.mgr=b.empno
join dept d on a.deptno=d.dpetno
from emp a , emp b , dept d
where a.empno=b.mgr and a.deptno=d.deptno;
from emp a join emp b on a.mgr=b.empno
join dept d on a.deptno=d.deptno
6. CROSS JOIN
7. ANTI JOIN
8. SEMI JOIN
VIEW
SEQUENCE
---------------------------
팀별로 조인 문제
------------------------
수요일 - DB 모델링 : 세미 팀 프로젝트 ?
------------------------
목/금 -PL/SQL
-- 토/일/월~프로젝트 금/토/일'Oracle' 카테고리의 다른 글
| [Oracle]days13 -데이터베이스 모델링 (0) | 2022.04.20 |
|---|---|
| [Oracle ]days12 - join (0) | 2022.04.19 |
| [Oracle] 달력만들기 (0) | 2022.04.18 |
| SQL funtion (0) | 2022.04.17 |
| [Oracle] days10 (0) | 2022.04.15 |

