
데이터정제
데이터 정제
BeautifulSoup(뷰티풀숩)을 통해 HTML 태그를 제거
정규표현식으로 알파벳 이외의 문자를 공백으로 치환
NLTK 데이터를 사용해 불용어(Stopword)를 제거
어간추출(스테밍 Stemming)과 음소표기법(Lemmatizing)의 개념을 이해하고 SnowballStemmer를 통해 어간을 추출
"""
header = 0 은 파일의 첫 번째 줄에 열 이름이 있음을 나타내며
delimiter = \t 는 필드가 탭으로 구분되는 것을 의미한다.
quoting = 3은 쌍따옴표를 무시하도록 한다.
"""

html태그 없애기
BeautifulSoup(train['review'][0], "html5lib")
특수기호 없애기
소문자로 변환한 후, spilt을 이용하여 문자를 나눈다.(토큰화)
불용어 제거
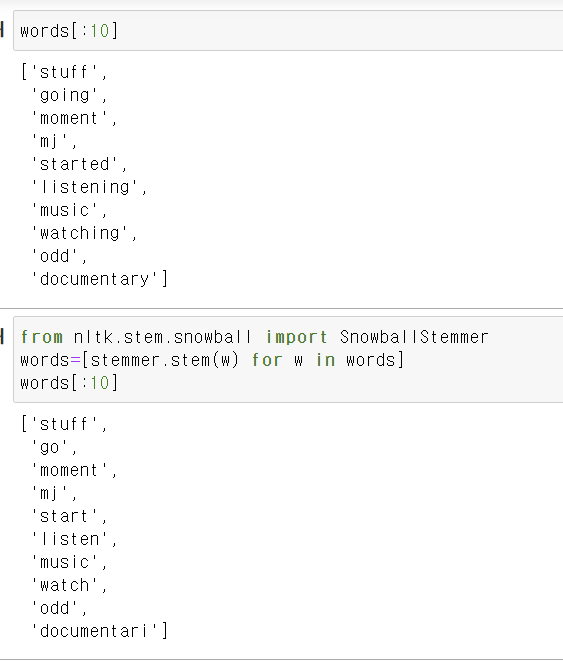
437개에서 219개로 줄음
스태밍 -어간 추출
어간 추출은 어형이 변형된 단어로부터 접사 등을 제거하고 그 단어의 어간을 분리해 내는 것
"message", "messages", "messaging" 과 같이 복수형, 진행형 등의 문자를 같은 의미의 단어로 다룰 수 있도록 도와준다.
NLTK에서 제공하는 형태소 분석기를 사용
포터 스태머 사용방법 과 랭커스터스태머 사용 방법
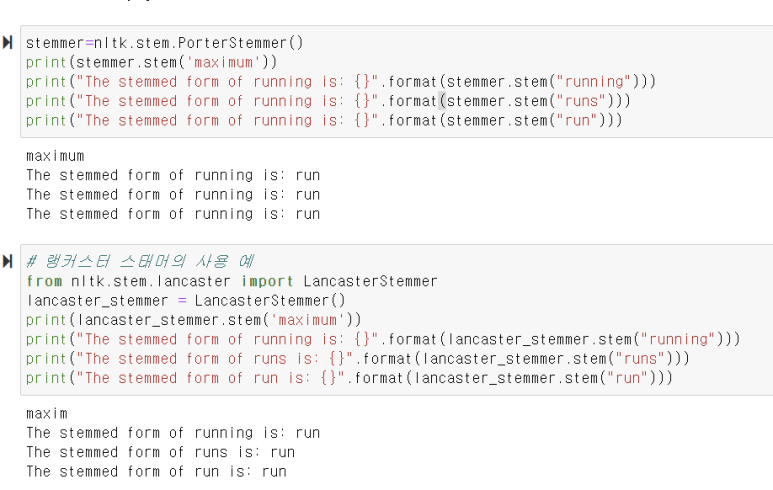
스노우볼 스태머를 사용해서 어간 변경
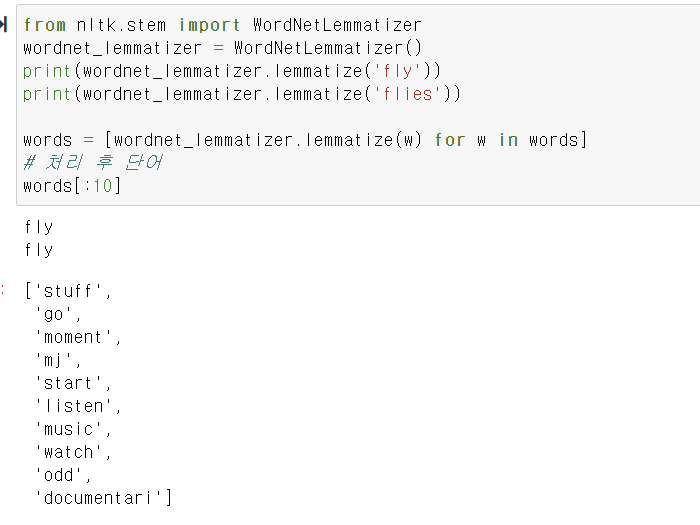
음소표기법 -Lemmatization
레마타이제이션은 이때 앞뒤 문맥을 보고 단어의 의미를 식별하는 것
배 - 먹는 배 , 타는 배, 몇 배 등 동음이의어가 문맥에 따라 다른 의미를 가진다.
meet- meeting은 회의, meet 만나다 명사로쓰였는지, 동사로 쓰였는지에 따라 적합한 의미를 갖도록 추출
지금 까지 한 것을 함수로 만들고 적용

multiprocessing 으로 전처리

워드클라우드