
Jam's story
[파이썬] 맵리듀스 초급 wordcount application 작동 ] 본문
1.mapper.py를 코딩하여 맵 스크립트를 작동
‘stdin’은 standard input 으로 맵과 리듀스 단계 코드 사이로 데이터를 패싱하는데 도움을 주는 하둡 스트리밍 API
STDIN는 인풋을 단어별로 쪼개는 과정이라고 생각하시면 되며,
STDOUT은 그들의 단어들을 카운트하는 맴의 라인 리스트라고 보시면 됩니다.
“/usr/bin/env: ‘python’: No such file or directory”
이러한 에러가 생겨서
파이썬을 설치하였다.
-리눅스 안 파이썬 설치코드
~/hadoop$ python --version
~/hadoop$ sudo apt update
~/hadoop$ sudo apt-get install python-is-python3
~/hadoop$ python3 -V
#!/usr/bin/env python
mapper.py
$ pwd
$ cd $HADOOP_HOME
~/hadoop$ mkdir mapreduce
~/hadoop$ cd mapreduce
~/hadoop/mapreduce$ pwd
~/hadoop/mapreduce$ nano /home/neuavenue/hadoop/mapreduce/mapper.py
import sys
# STDIN(Standard Input) 기초 입력(인풋데이터)로 부터 온 데이터 라인별로 실행
for line in sys.stdin:
# 문장의 스페이스 꼬리부분들과 앞부분을 제거하는 함수
line = line.strip()
#문장 내의 라인들을 쪼개는 작업
words = line.split()
# 해당 모든 단어별로 임의의 숫자를 증가시켜면서 STDOUT(Standard Output)
# 기본 아웃풋 곧 출력물이자 결과값을 읽는 작업..
# 파일 내의 모든 단어 갯수만큼 루프를 돌면서 1로 밸류값을 지정하고,
# 모든 단어를 키 값으로 넣어 전체를 나열하여 결과값으로 프린트.
# %s - 단어들을 스트링으로 출력하고자 할 때 사용
# %t - 프린트할 때 탭을 출력하고자 할 때 사용
for word in words:
print( '%s\t%s' % (word, 1))
~/hadoop/mapreduce$$ ls -l
~/hadoop/mapreduce$$ chmod +x mapper.py
chmod -x mapper.py 를 써서 읽기 권한 쓰기를 바꾼다
-rw -이부분이 달라짐

리듀스파일 생성하기
~/hadoop/mapreduce$ nano reducer.py
mapper.py 와 reducer.py의 경로지정이 다르다 - > 같은 경로내에서 실행하기때문에
경로를 지정하지 않는 한 같은 디렉토리에서 상이한? 파일을 만들 수 있음
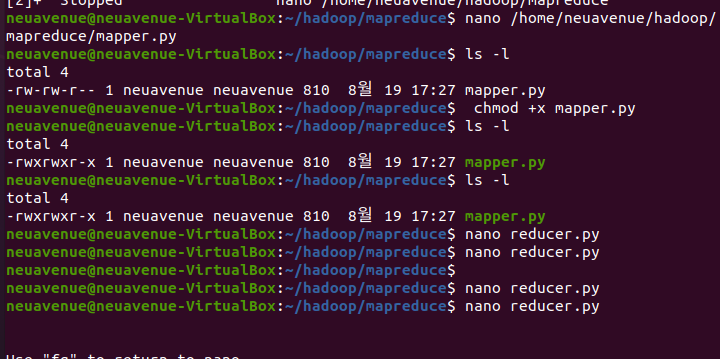
-ls 명령어로 파일확인 한다.
-chmod로 reducer.py의 읽기 쓰기를 바꾼다
-ls -l 읽기쓰기 모드로 바뀌었는지 확인
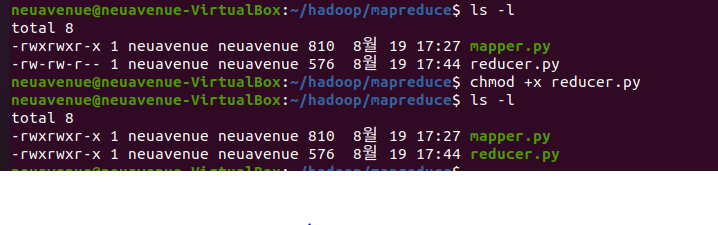
파이썬 코드테스트
~/hadoop/mapreduce$ echo Here is a lion that is roaring my ear | ~/hadoop/mapreduce/mapper.py
~/hadoop/mapreduce$ echo Here is a lion that is roaring my ear | ~/hadoop/mapreduce/mapper.py | sort -k1,1 | ~/hadoop/mapreduce/reducer.py
구글 혹은 파이어폭스 웹 브라우저에서 Gutenberg.org 사이트로 이동하셔서
원하시는 ebook 파일 두 개 이상을 다운 받습니다.
~/hadoop/mapreduce$mkdir input
http://www.gutenberg.org/ebooks/64846
http://www.gutenberg.org/cache/epub/13998/pg13998.txt
혹은 온라인 북의 컨텐츠를 복사하셔서 우분투 리눅스 로컬 시스템에 새로운 파일을 생성합니다.
~/hadoop/mapreduce/input$ nano the-plant-of-illusion-by-Donald-A-Wollheim.txt
~/hadoop/mapreduce/input$ nano Ireland-And-The-Home-Rule-Movement.txt
-input 폴더를 만들고 그 폴더로 이동
-텍스트 파일을 만들고, 그 안에 ebook에서 다운받은 파일을 넣는다.

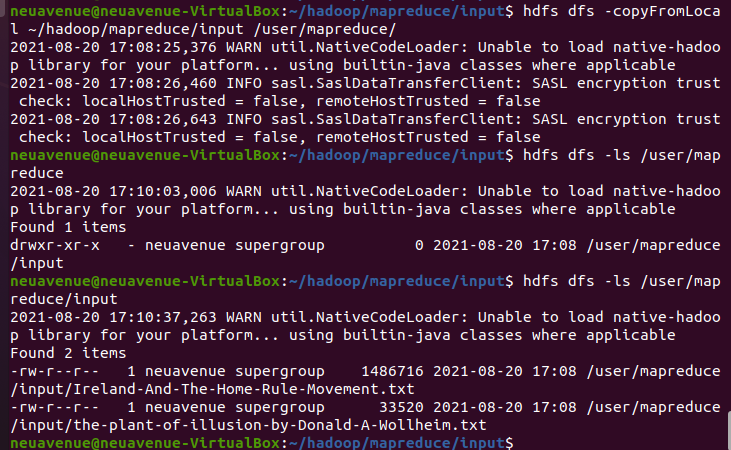
copyfromLocal 로컬의 파일을 하둡의 분산파일로 이동시킨다.
hdfs dfs -copyFromLocal ~/hadoop/mapreduce/input /user/mapreduce
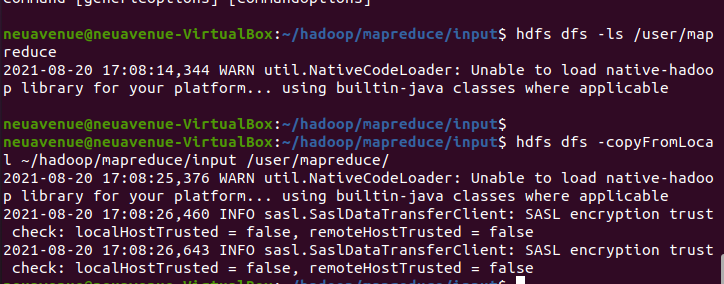
/user/mapreduce로 이동 잘했나 -ls를 ㅎ통하여 확인한다.
hdfs dfs -ls /user/mapreduce
맵리듀스 잡 실행
~/hadoop/mapreduce$ hadoop jar ~/hadoop/share/hadoop/tools/lib/hadoop-streaming-3.2.1.jar \
-file ~/hadoop/mapreduce/mapper.py -mapper ~/hadoop/mapreduce/mapper.py \
-file ~/hadoop/mapreduce/reducer.py -reducer ~/hadoop/mapreduce/reducer.py \
-input /user/mapreduce/input/* -output /user/mapreduce/output-ebook
localhost:9870 에 들어가서
utility -> browse the file system 을 클릭한다.
경로에 input. output 둘다 잘 들어있나 확인한다.
'2021-2학기 > 하둡' 카테고리의 다른 글
| Mapreduce_ java_wordcount (0) | 2022.03.23 |
|---|---|
| eclipse 아이콘 보이게 하기 (0) | 2022.03.23 |
| WordCount MapReduce Application (0) | 2022.03.23 |
| 궁금했던것 질문과 답변 (0) | 2022.03.23 |
| 하둡 사용자 명령어 2 (0) | 2022.03.23 |

